本文是 CMU Seminar 2025 年 3 月 31 日的讲座总结,讲座主题是 StarRocks Query Optimizer。
-
CMU Seminar 视频:StarRocks Query Optimizer (Kaisen Kang)
-
CMU Seminar PDF:StarRocks Query Optimizer (Kaisen Kang)
-
本文的英文版博客: StarRocks Query Optimizer
StarRocks 查询优化器概览
Development History of StarRocks
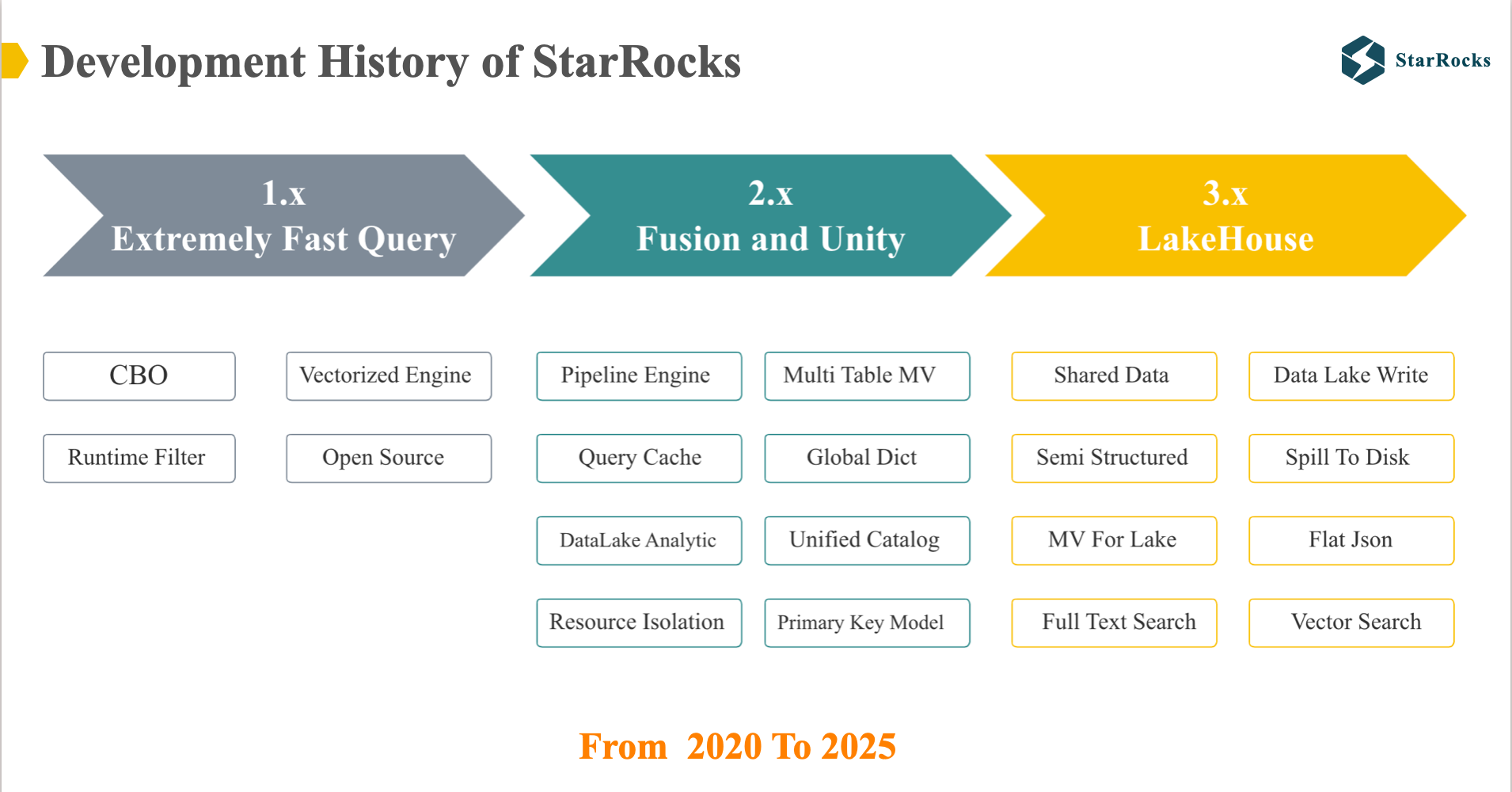
过去 5 年,StarRocks 发布了 3 个大版本:
- StarRocks 1.0: 通过 向量化引擎 和 CBO 打造了一个极速的 OLAP 数据库
- StarRocks 2.0: 通过 主键模型,数据湖分析,查询引擎的进一步优化 打造了一个极速,统一的 OLAP 数据库
- StarRocks 3.0: 通过 存算分离,物化视图,数据湖分析 打造了一个 Open LakeHouse
StarRocks Architecture
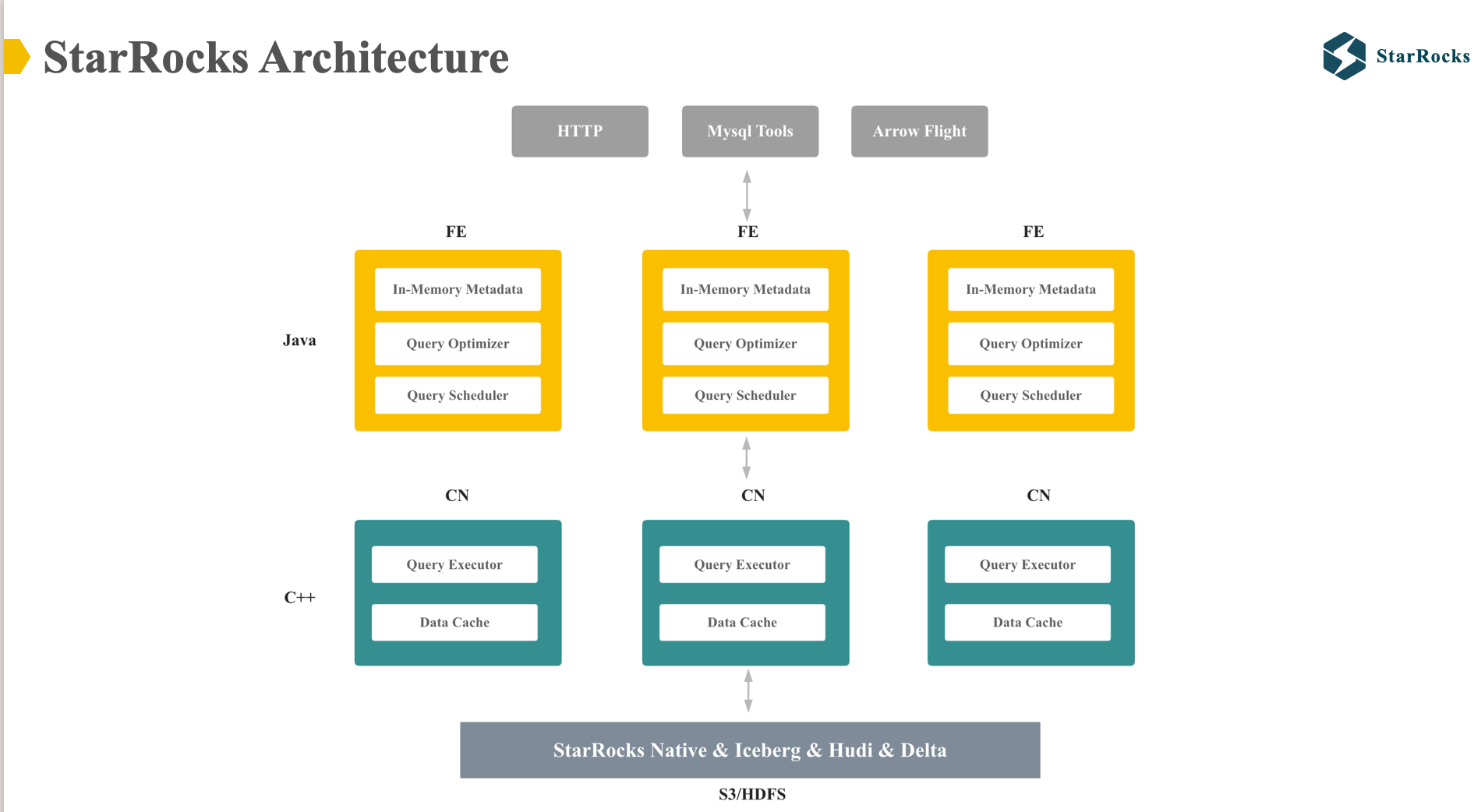
图中展示了 StarRocks 的整体架构,分为 Frontend 和 compute node 两个核心组件:
- FE: 主要包括元数据,查询优化和查询调度,由 Java 实现
- CN: 主要包括 lake 数据上的 data cache 和查询执行引擎,由 C++ 实现
StarRocks Optimizer OverView
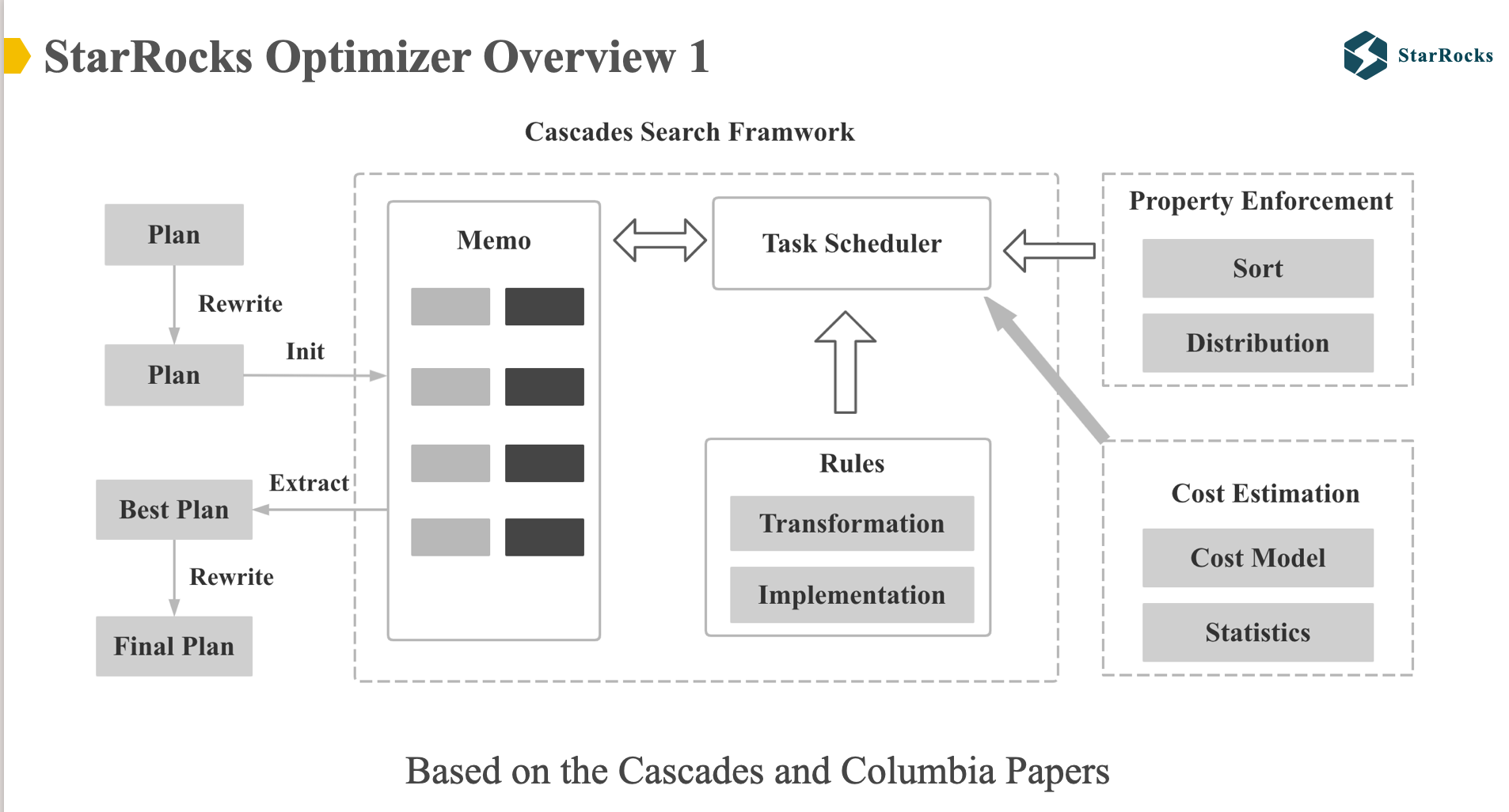
图中展示了 StarRocks 优化器的整体架构,StarRocks 优化器 整体框架是根据 Cascades 和 Columbia 论文实现的。 StarRocks 优化器的搜索框架,Rule 框架,Property Enforce 机制都是和 Cascades 框架一致。
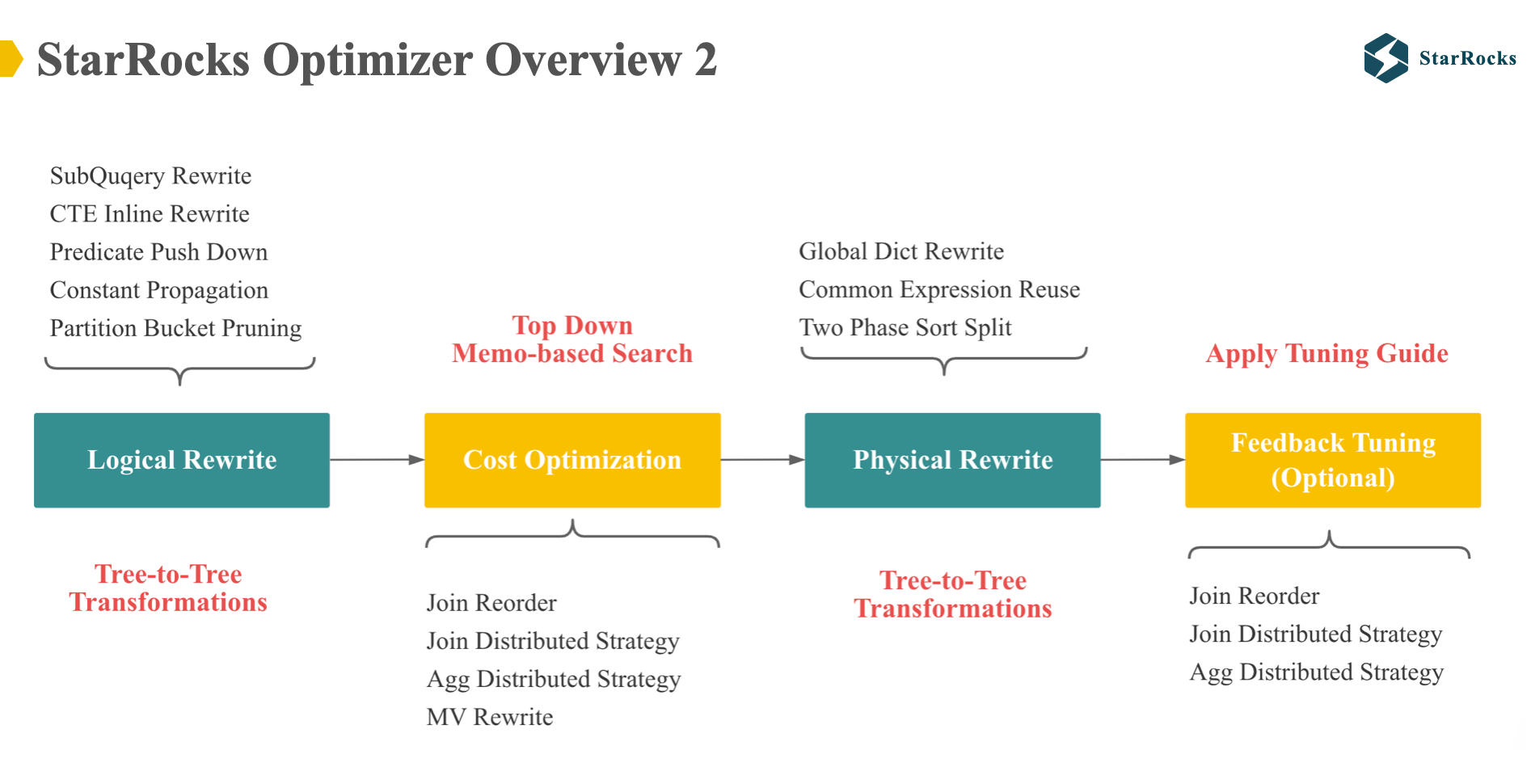
图中展示了 StarRocks 优化器更详细的优化流程,也体现了几处和 Cascades 框架的 Diff
-
首先,StarRocks Optimizer 是多阶段的,依次有 Logical rewrite, Cost based Optimization, Physical rewrite and Feedback Tuning
-
其中, Logical rewrite is tree-to-tree transformation, 包括很多常见的 rewrite rule: 子查询改写,CTE inline 改写,谓词下推,列裁剪等
-
Cost based Optimization 是基于 Cascades Memo 实现的,包括几个很重要的 cost based rules: Join reorder, Join distributed strategy, Aggregate distributed strategy, MV Rewrite.
-
Cost based Optimization 的输出是一棵分布式的 physical tree,然后 physical rewrite 阶段会进行少数不影响 Cost 的 physical rewrite,包括今天要分享的 Global Dict Rewrite,以及常见的公共表达式复用等。
-
最后的 feedback tuning 是 24 年新实现的功能,下文会分享到,feedback tuning 会根据运行时 feedback 的信息调整执行计划。
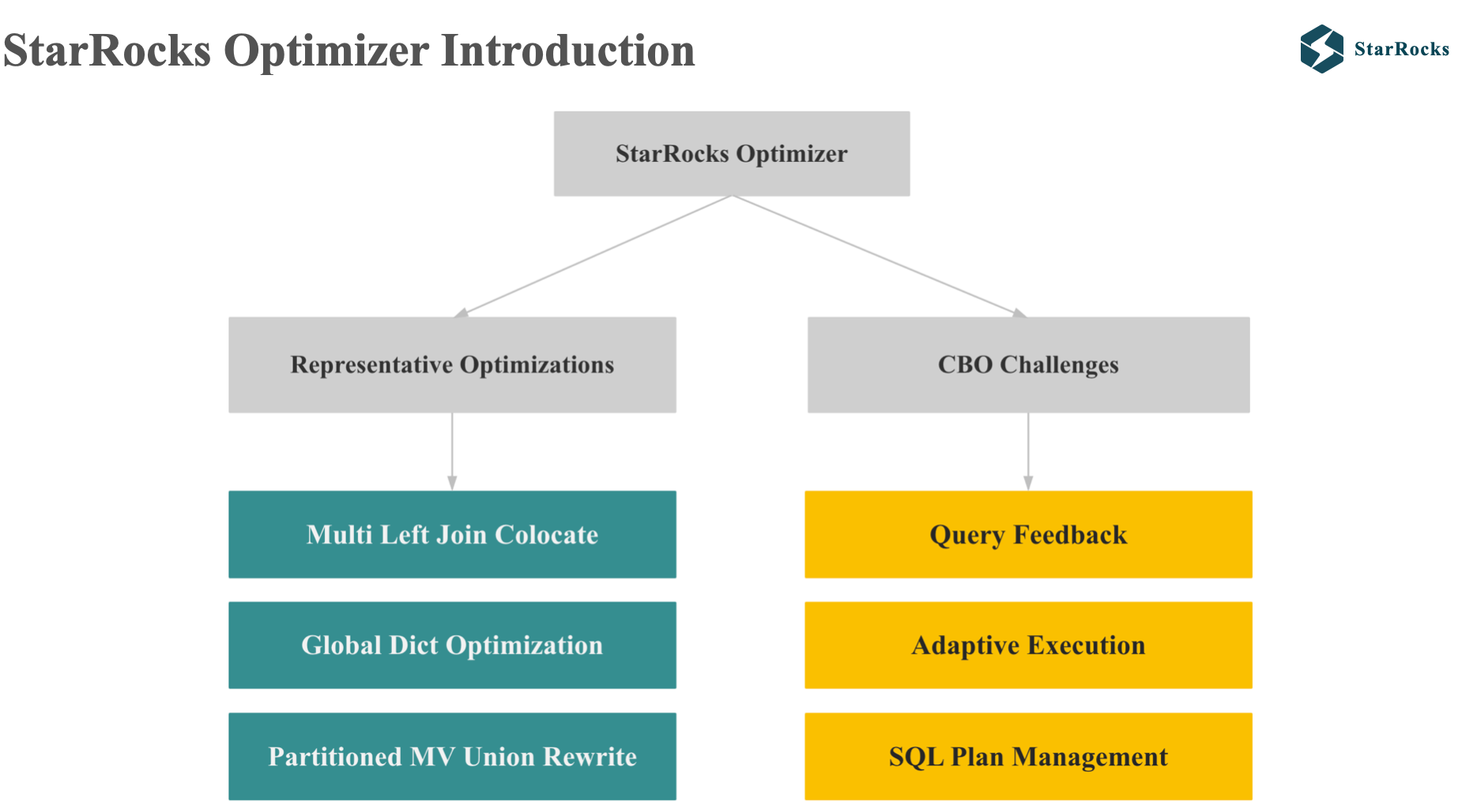
现在我们对 StarRocks 和 StarRocks Optimizer 有了整体的了解,下面我们再深入了解下 StarRocks Optimizer,我主要会从 2 方面进行分享:3 个有代表性的优化和 StarRocks 应该 Cost 估计的常见问题的解决方案:
-
3 个优化包括:Multi left Join colocate, Global dict optimization, partition mv union Rewrite.
-
3 个应对 Cost 估计问题的解决方案包括:Query Feedback,Adaptive execution, SQL plan management
三个代表性优化
Multi Left Join Colocate
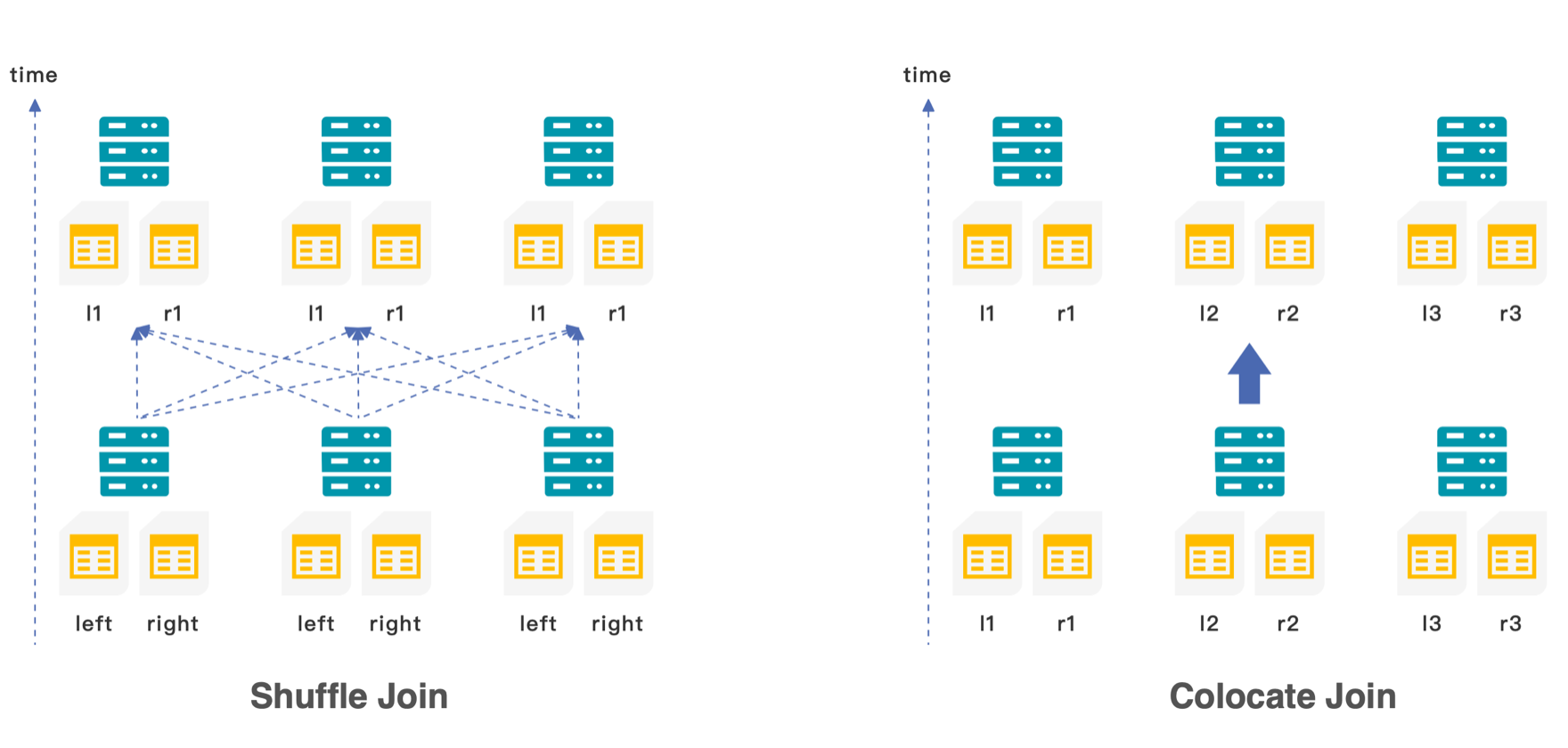
在了解 Multi left Join colocate 之前,我们先看下什么是 Colocate join。我们知道,在分布式数据库中,Join 的分布式执行策略包括:Shuffle join,Broadcast join,Replication join,Colocate join
-
Shuffle join 是指在 join 之前需要将两表的数据按照 join 的 key shuffle 到相同的执行节点上
-
Colocate join 是指 join 的两表的数据已经根据 join 的 key 提前分布在相同的节点上,可以直接 local join,不需要网络传输
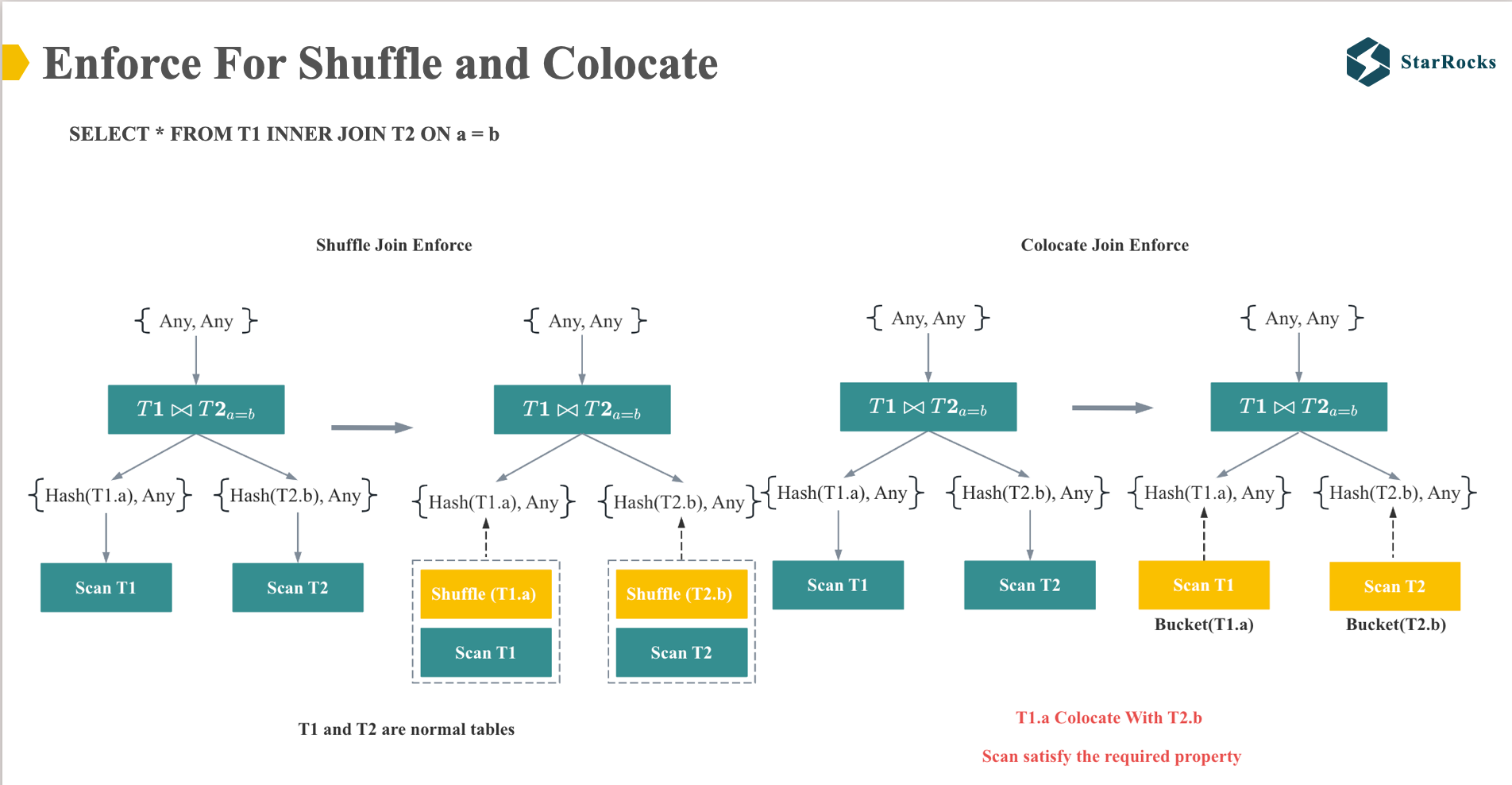
在 StarRocks,我们依靠 distribution property enforcer 决定 join 的分布式策略。
左边是 Shuffle Join enforcer 的示例,join 会 require hash(T1.a)和 hash(t2.b)的 property,因为 T1 和 T2 是正常的表,不满足 hash(T1.a) 和 hash(t2.b)的分布,所以会在 Scan T1 和 Scan T2 的 operator 上 enforce 出 shuffle 的 exchange 节点。
右边是 Colocate Join enforce 的示例,join 同样会 require hash(T1.a)和 hash(t2.b)的 property,但是 T1 和 T2 是 colocate 的表,而且按照 t1.a 和 t2.b hash 分布,所以满足 join require 的 property,无需添加 shuffle 节点,可以直接 local join.
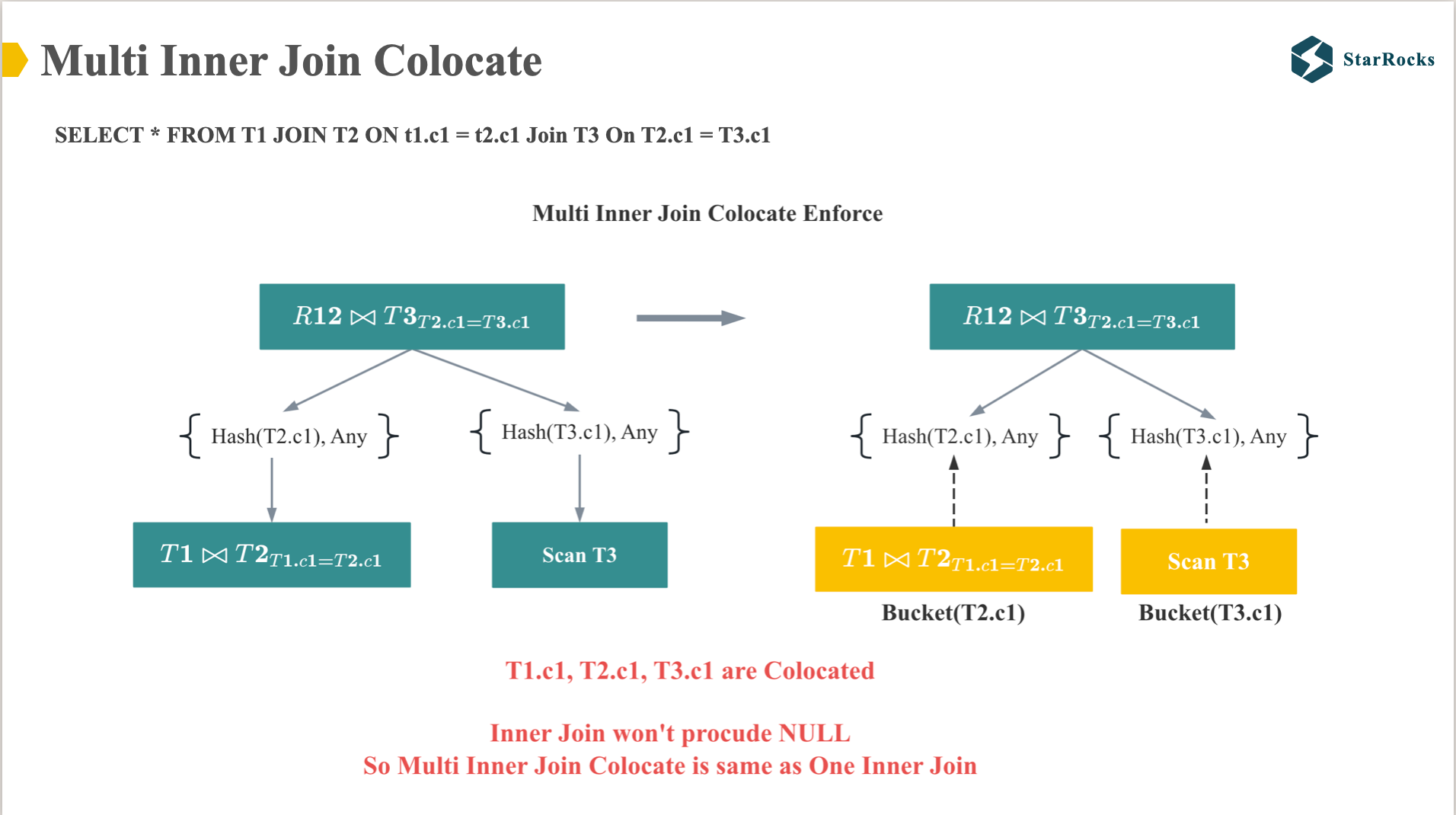
下面我们来看下多表 inner join 的 colocate。 大家从图中可以看到,当 T1,T2,T3 按照各自的 bucket column colocate 后,两表 join 的 colocate 过程和多表一样,都可以直接 colocate。因为 T1 和 T2 Inner join 后,join 结果的物理分布和 T1 或者 T2 完全相同。
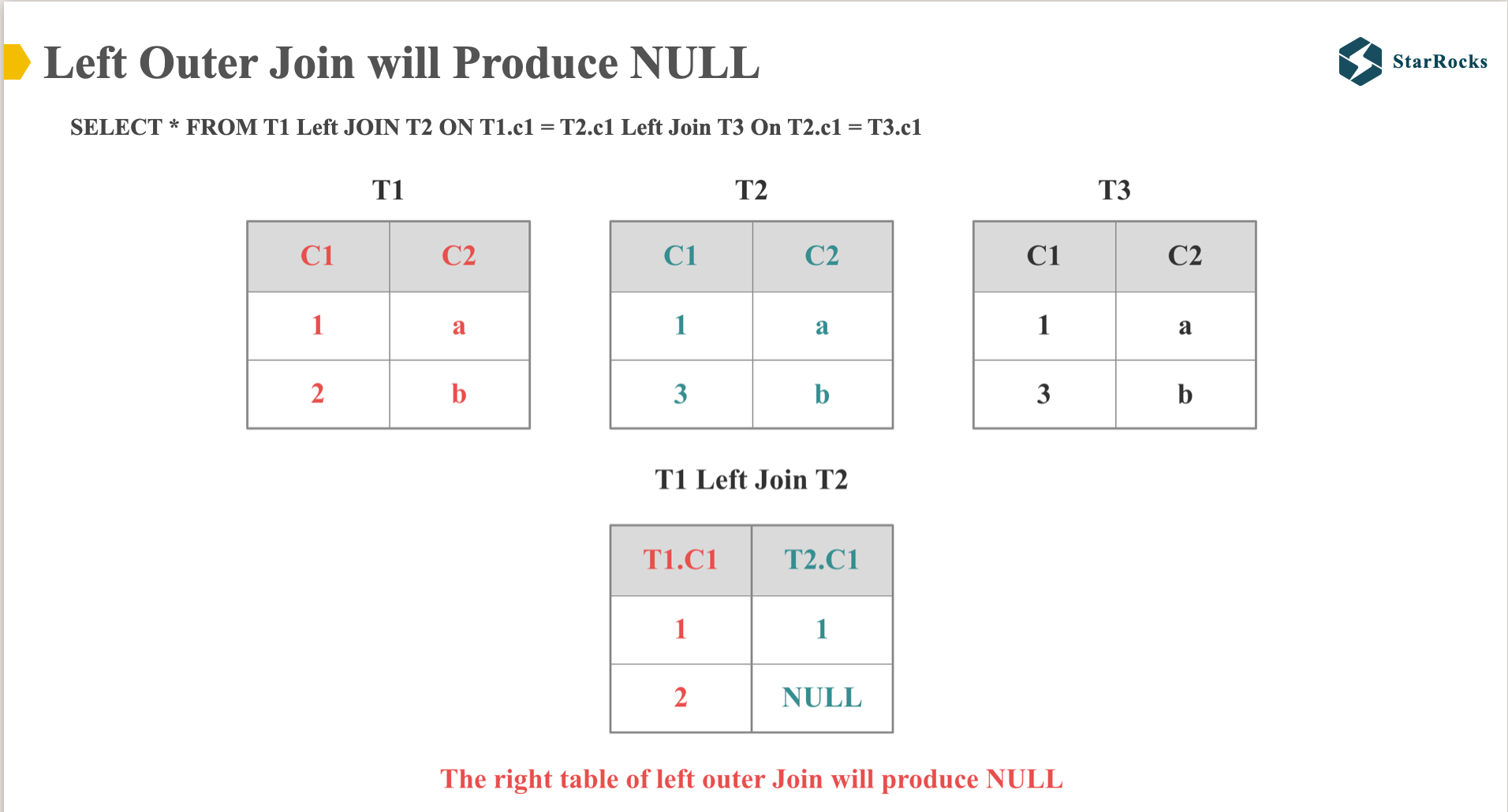
在介绍 Multi Left Join Colocate 前,我们先确认下 left join 和 inner join 的核心区别:
我们都知道,Left Join 会保留左表的数据,右表 join 不上的数据会补 NULL。 如图,T2 表 C1 列的第二行数据变成了 NULL
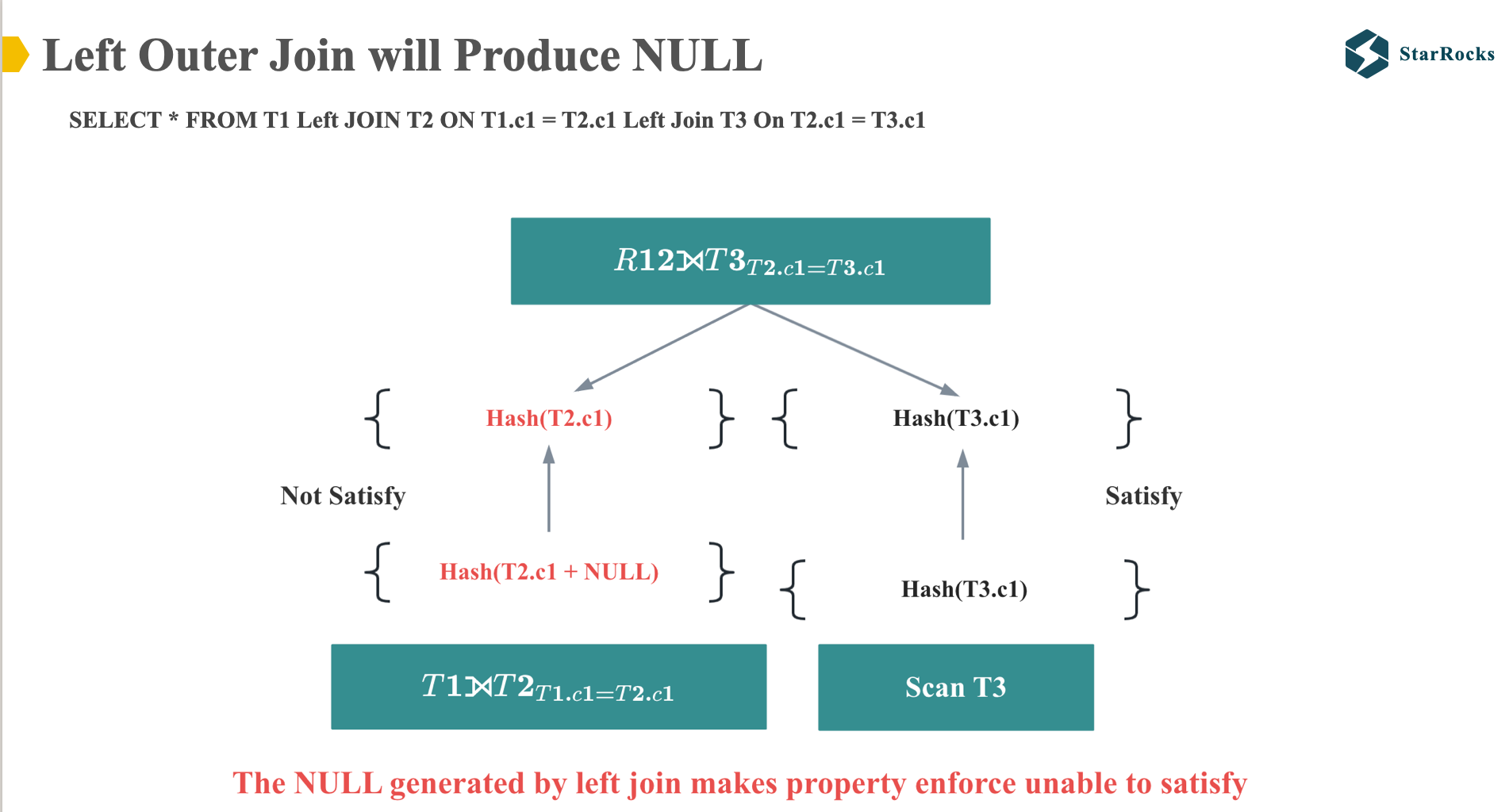
因此,当应用多表 Left Join 分布属性 enforce 时,Left Join 后得到的 T2 表的 C1 列与原始 T2 表的 C1 列不同,从而阻止了 Colocation Join 的执行。
但是,我们进一步分析一下,看看这个 left join SQL 是否真的不能做 Colocate Join。
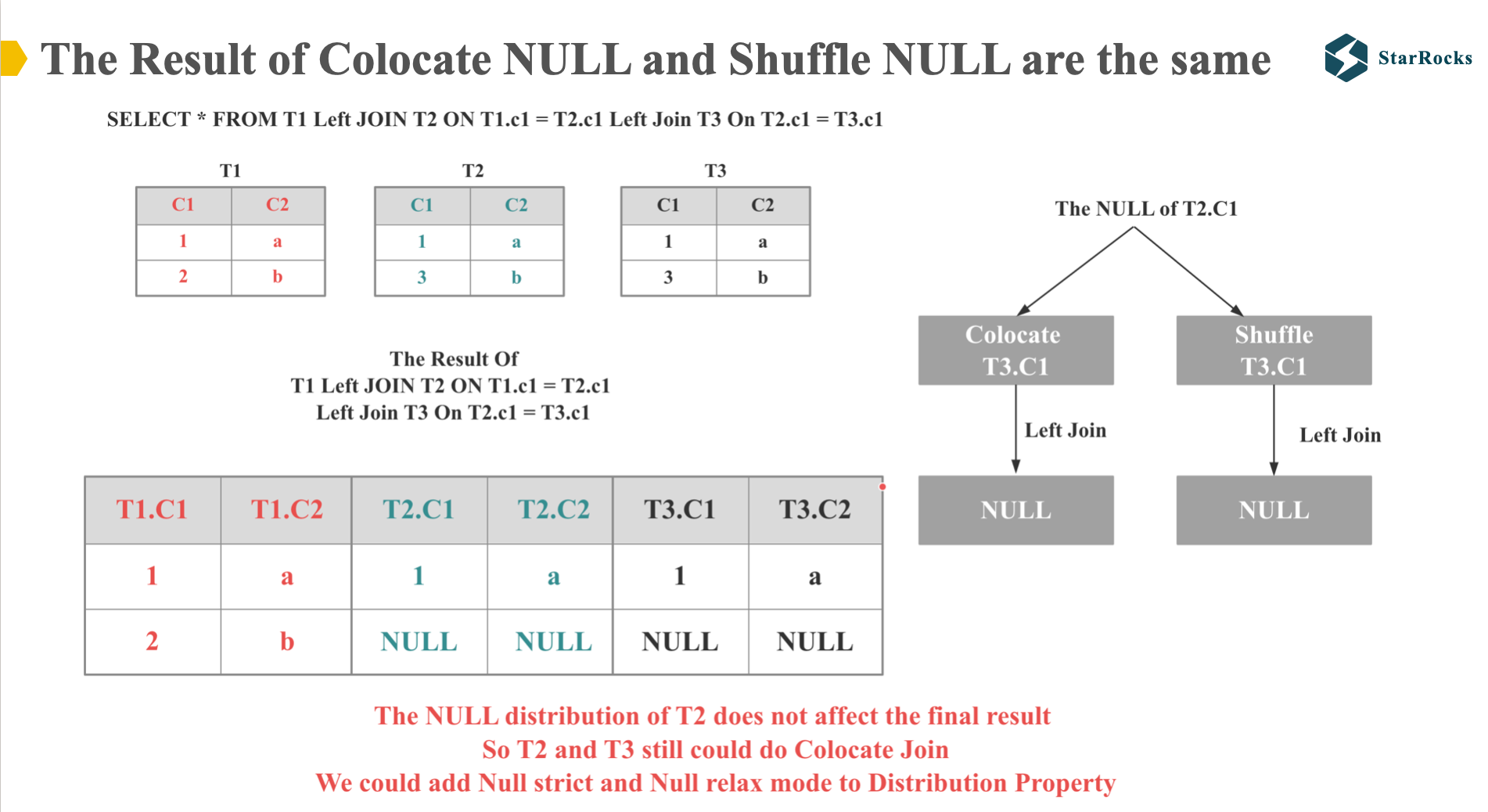
大家可以先看左边的表格,是这个 left join SQL 执行的正确结果。
然后大家再看右边,请思考下 T2.C1 的 NULL 值在 colcate 和 shuffle join 的情况下,是否会产生不同的结果。 我们知道,对于 NULL equal 任何值, 结果都会是 NULL,也就是说,无论 T2.c1 的 NULL 值和对应的 T3.C1 如何分布,是否在同一个节点上,join 的结果都是 NULL。
所以我们就可以得出,NULL 值的分布对 T2 和 T3 表否是可以 colocate join 没有影响。
因为 T2 和 T3 表除 NULL 外的值,都满足 Colocate 分布,所以 T2 和 T3 表依然可以 colocate join。
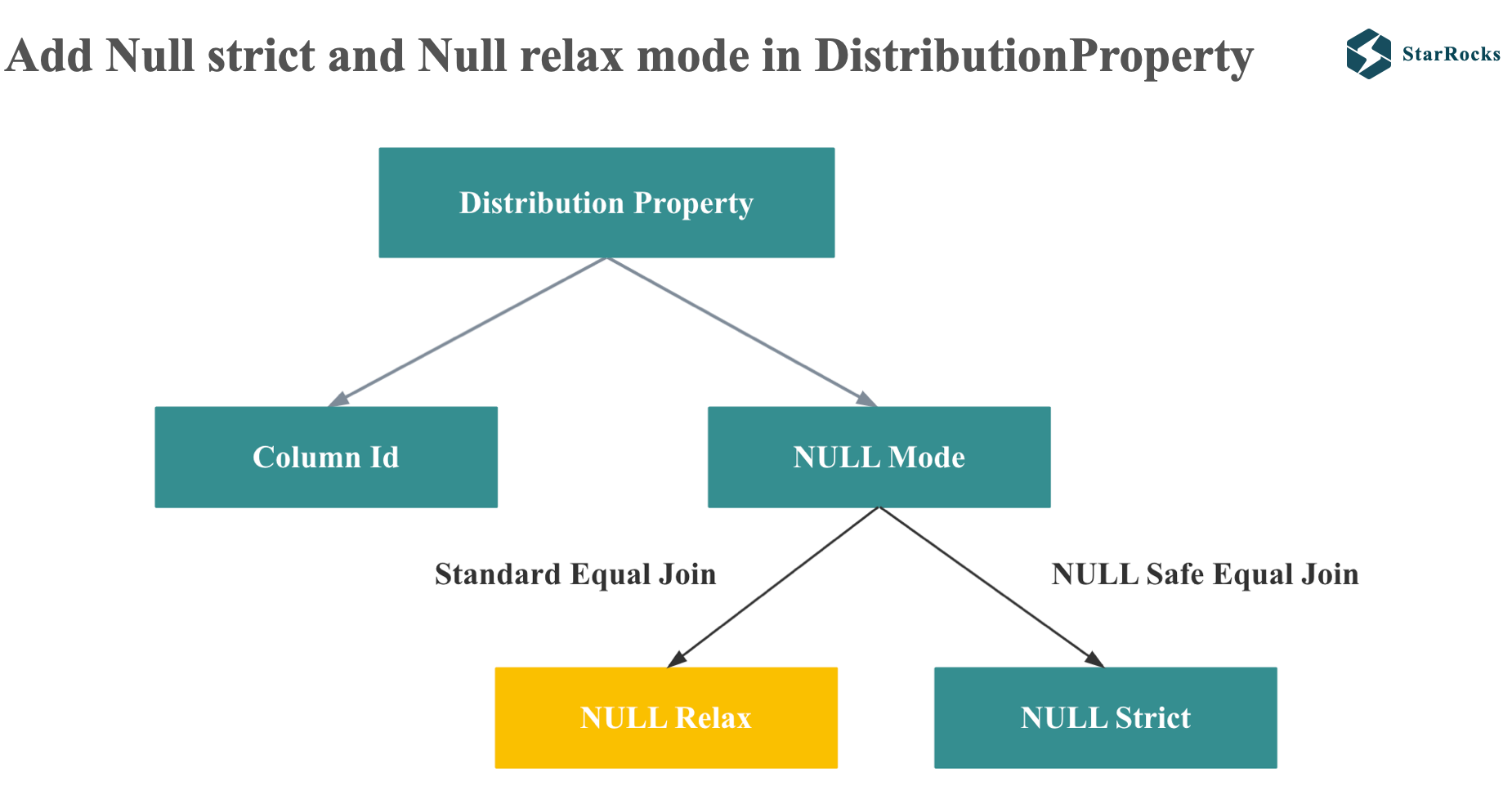
所以为了让 distribution property enforcer 可以支持这种情况,StarRocks 在 distribution property 引入了 NULL relax 和 null strict mode
对于 null rejecting 的 join on 谓词,StarRocks 就会生成 NULL relax mode,在 property 比较的时候会忽略 NULL
对于 null safe equal join, StarRocks 会生成 NULL strict model,在 property 比较时不能忽略 null
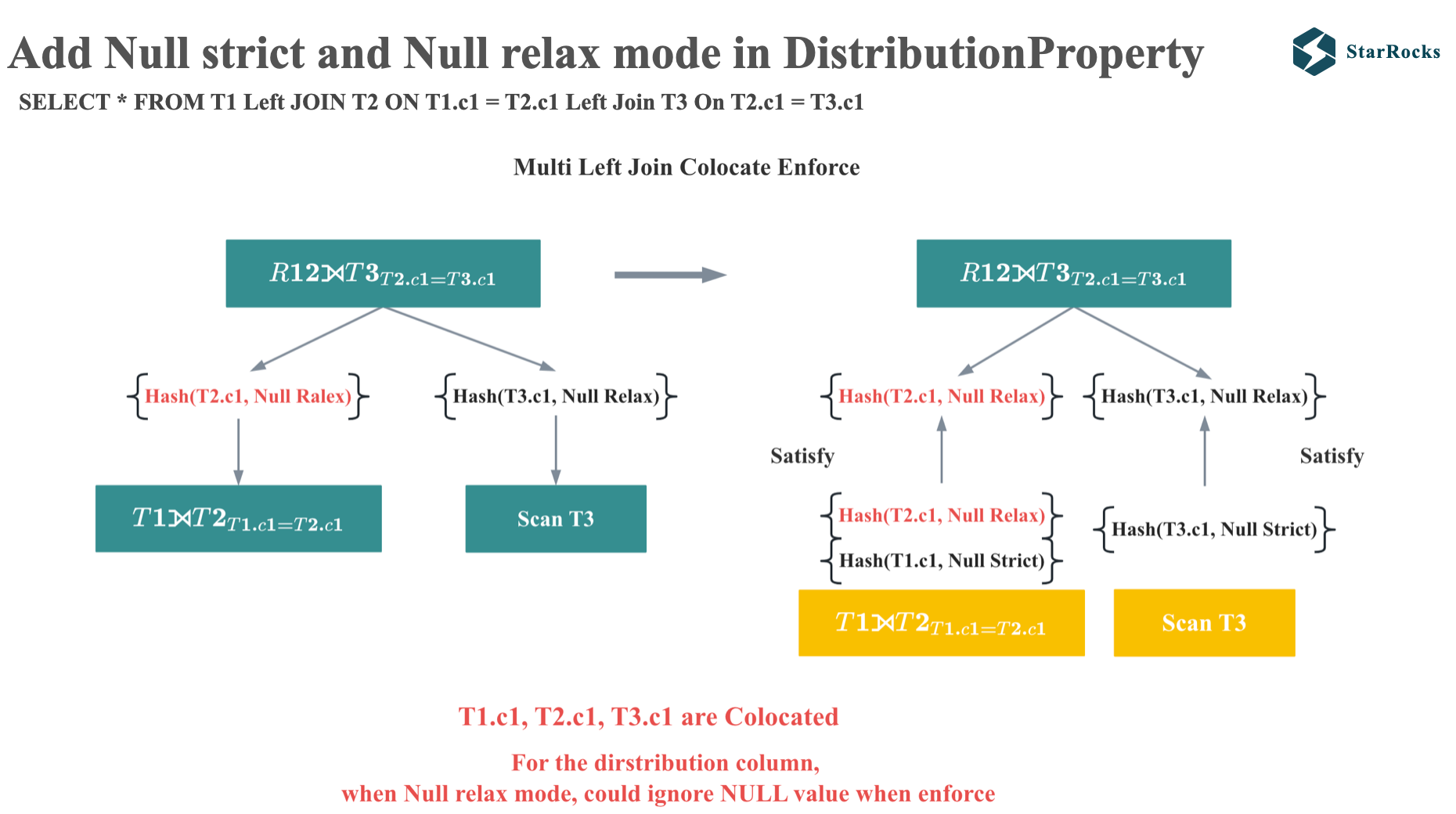
有了 NULL-relaxed 和 NULL-strict mode,我们现在再看下多表 Left Join 的 enforce 过程。
由于 T2.C1 处于 NULL-relaxed 模式,因此它在执行过程中满足父节点的分布式属性要求,从而可以实现 Colocation Join。
Low Cardinality Global Dict Optimization
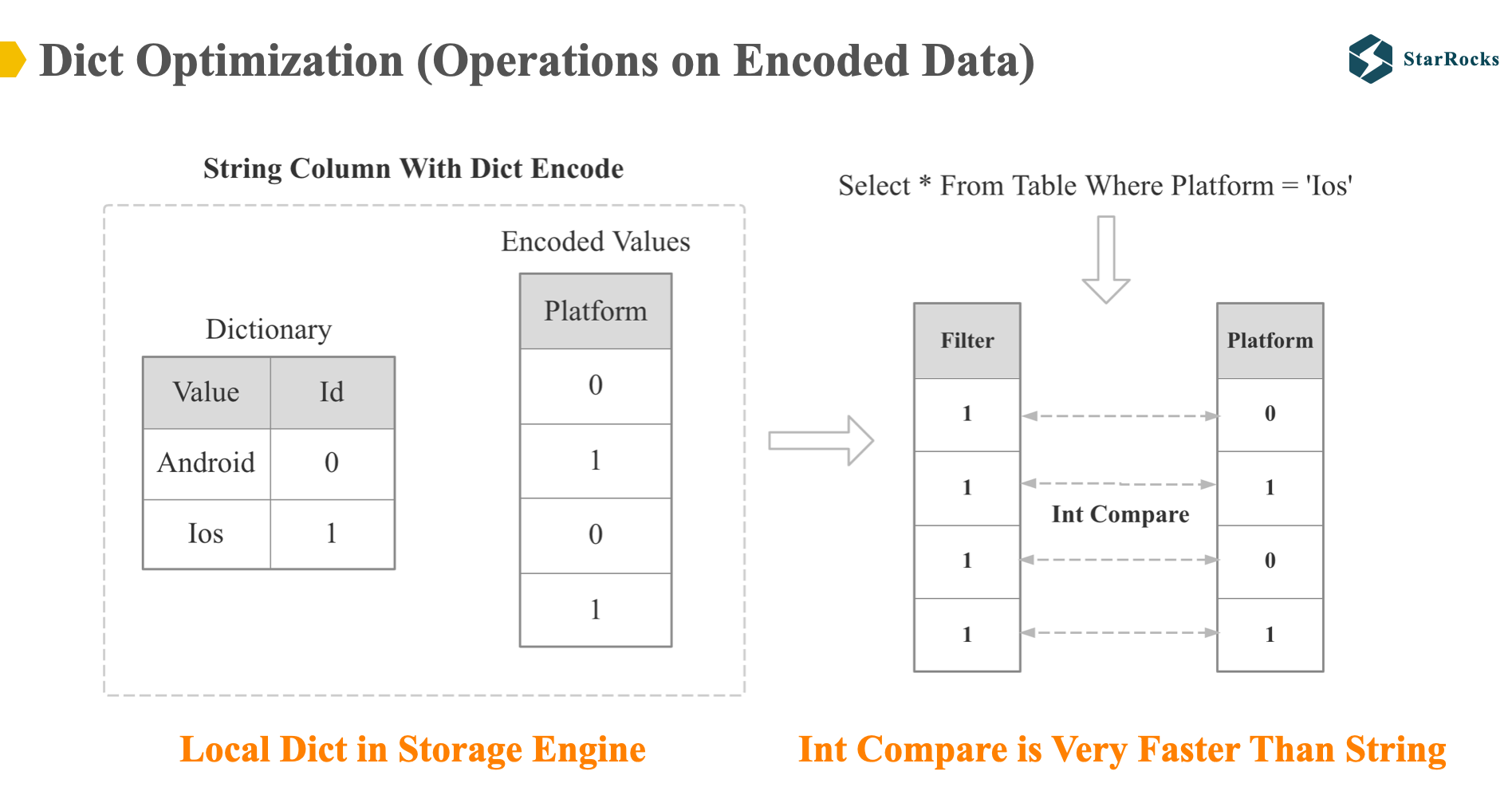
下面我们来看下低基数全局字典优化,我们首先看下什么是字典优化。字典优化就是 Operations on Encoded Data,对于字典编码的数据,直接基于编码的数据进行计算,而不需先解码再计算。
如图中所示,platform 这一列在存储层是字典编码,所以对于 platform 的过滤操作,会直接基于编码后的 int 数据进行操作,int 会比 string 的 compare 快很多。
存储层的 Dict Optimization 是 starrocks 1.0 就支持了,但是只支持 filter 操作,优化场景十分有限。 所以在 starrocks 2.0,我们支持了全局低基数字典的优化。

这里的一个关键词是低基数,因为如果基数很高,在分布式系统中,维护全局字典的成本就会很高。 所以我们目前基数限制的比较低,默认配置是 256,对于生产环境的很多维度表字段,256 可以 cover 足够多的字符串列。
Starrocks 的全局字典是对用户完全透明的。
有了全局字典之后,我们的字典优化就可以支持更多的算子和函数:Scan,Agg, join, 很多常用的字符串函数。 图中展示的是一个全局字典优化 group by 的示例:首先,StarRocks 维护了 city 和 platform 两列的全局字典,当进行 group by 操作时,StarRocks 就会将按照字符串 group by 变成按照 int group by,这样 Scan,Hash, equal 和 memcpy 等操作都会有一个显著的提速。 整个聚合查询会有一个 3 倍左右的提升。
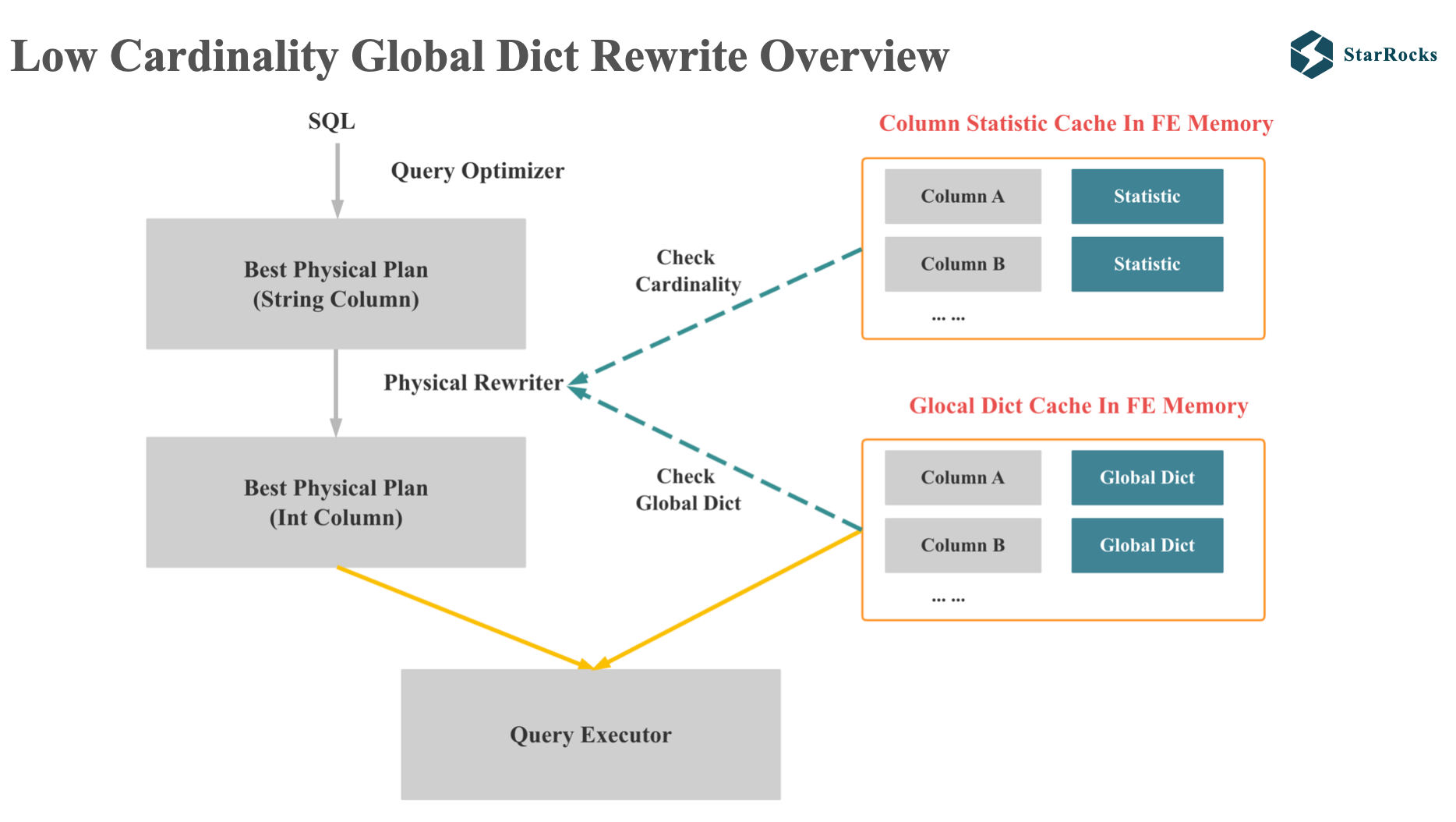
因为本文是优化器的分享,所以我们来重点关注下 StarRocks 如何利用全局字典改写 plan。
图中是全局字典改写 plan 的整体示意, 首先,改写是发生在 physical rewrite 阶段,我们会基于 CBO 产生的最优的分布式的 physical plan,将可以进行低基数优化的字符串列改写成 int 列。
要进行成功的改写,需要满足两个条件:
- Plan 中的字符串列是低基数列
- FE 的内存中拥有字符串列对应的全局字典
改写成功后,会将低基数字符串列对应的全局字典和执行 plan 一起发送查询执行器。
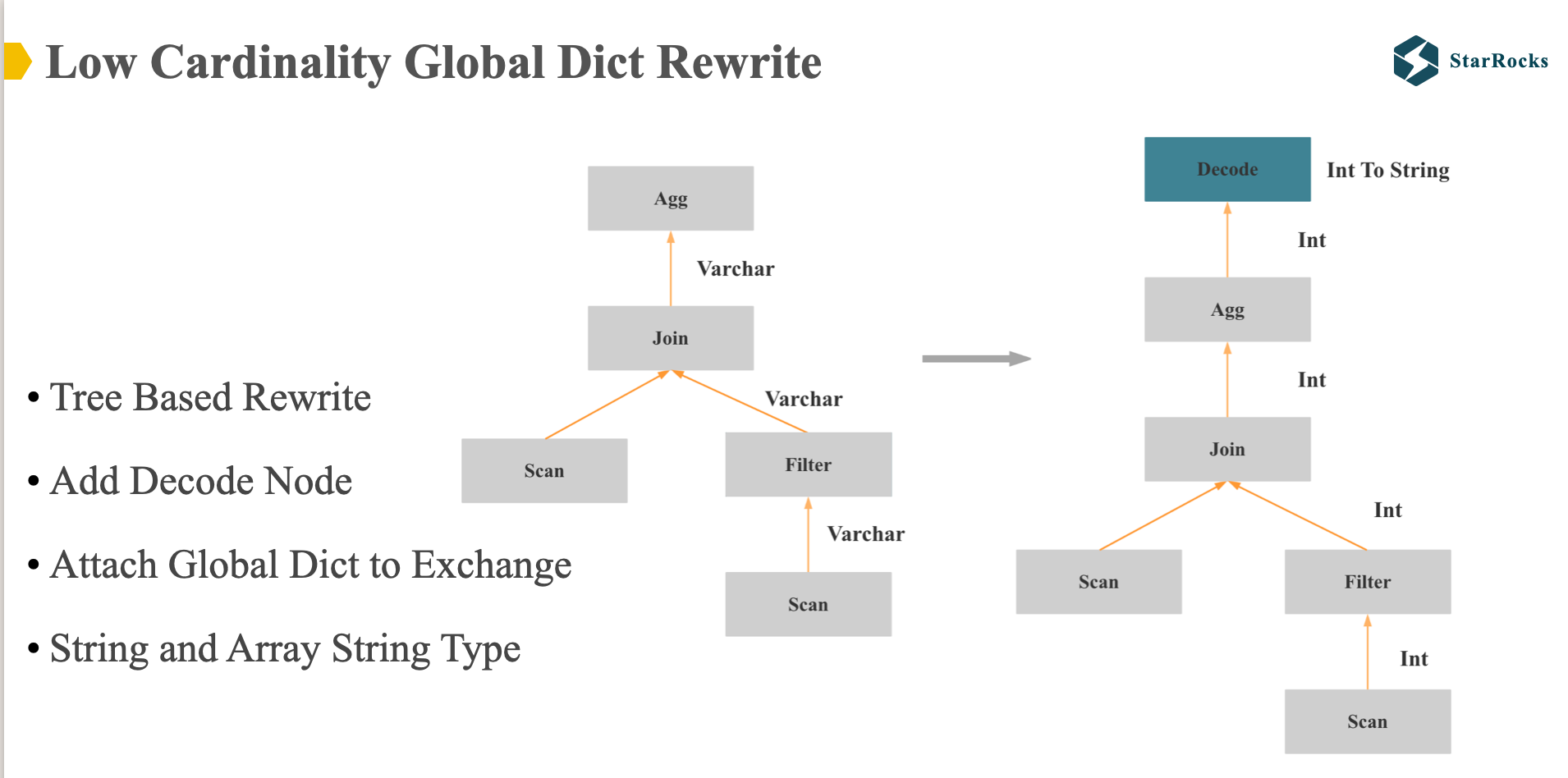
下面是一个全局字典改写整个 plan 的具体示意,目前 StarRocks 支持对于 string 和 array string 类型进行优化,(当然,理论上也可以扩展到其他类型)。
整个改写是 基于 physical tree 进行的,整个改写是 bottom up 的方法,如果发现某个 string 列可以进行低基数优化,就会改写成 int 列,同时用到这个列的所有字符串函数,聚合函数都要进行相应的修改,如果到某个节点,发现不能进行低基数优化,就会插入 decode node,在 decode node,就会将 int 列再解码成 string 列。
Partitioned MV Union Rewrite
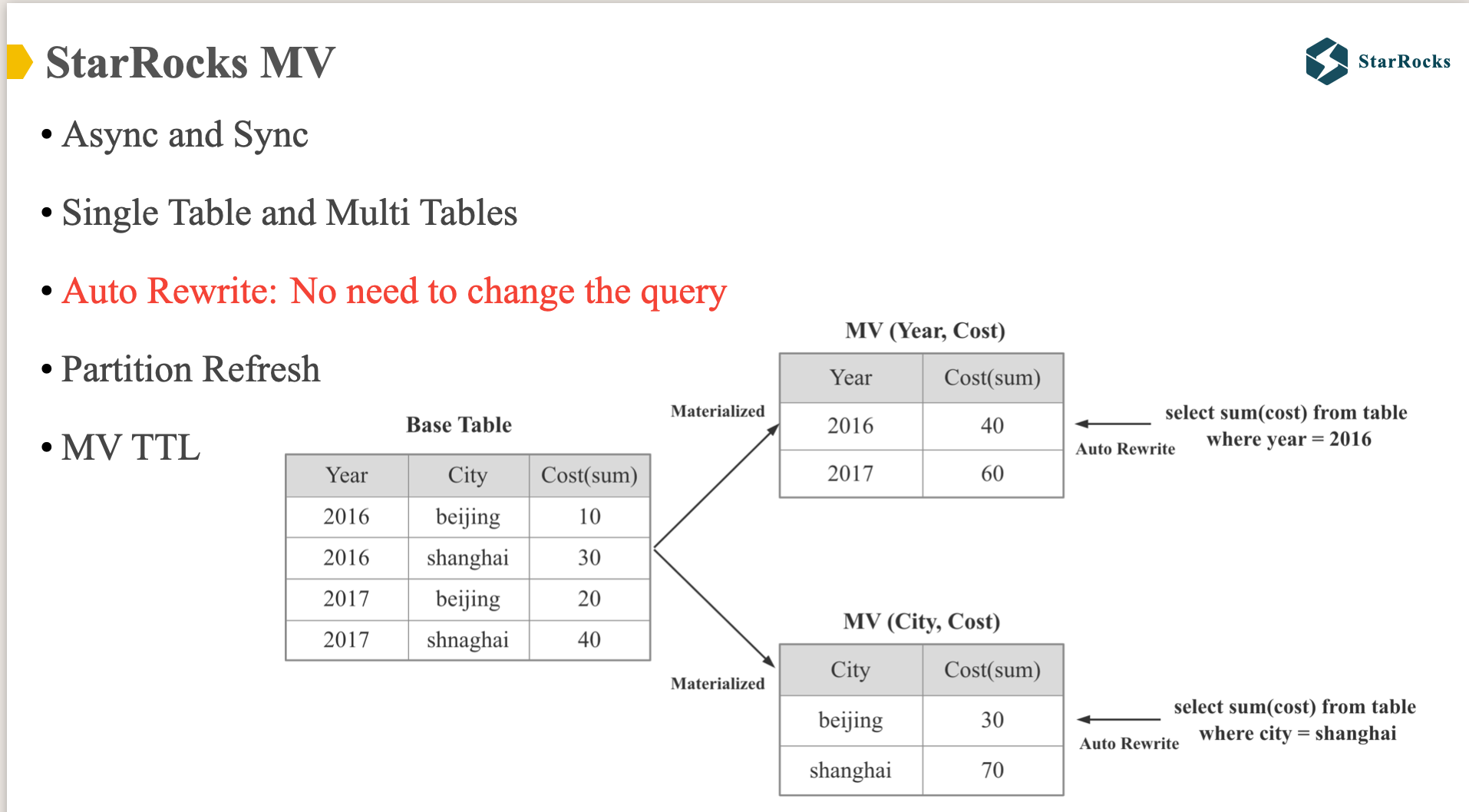
StarRocks 从 1.0 就支持同步 MV,从 2.0 开始就将 MV 提升到核心 feature 的地位。支持了全新的异步 MV,从之前的单表 MV 支持到多表 MV,同时在 MV 查询自动改写方面做了大量的优化改进。 今天的分享会集中在 MV 查询改写部分。
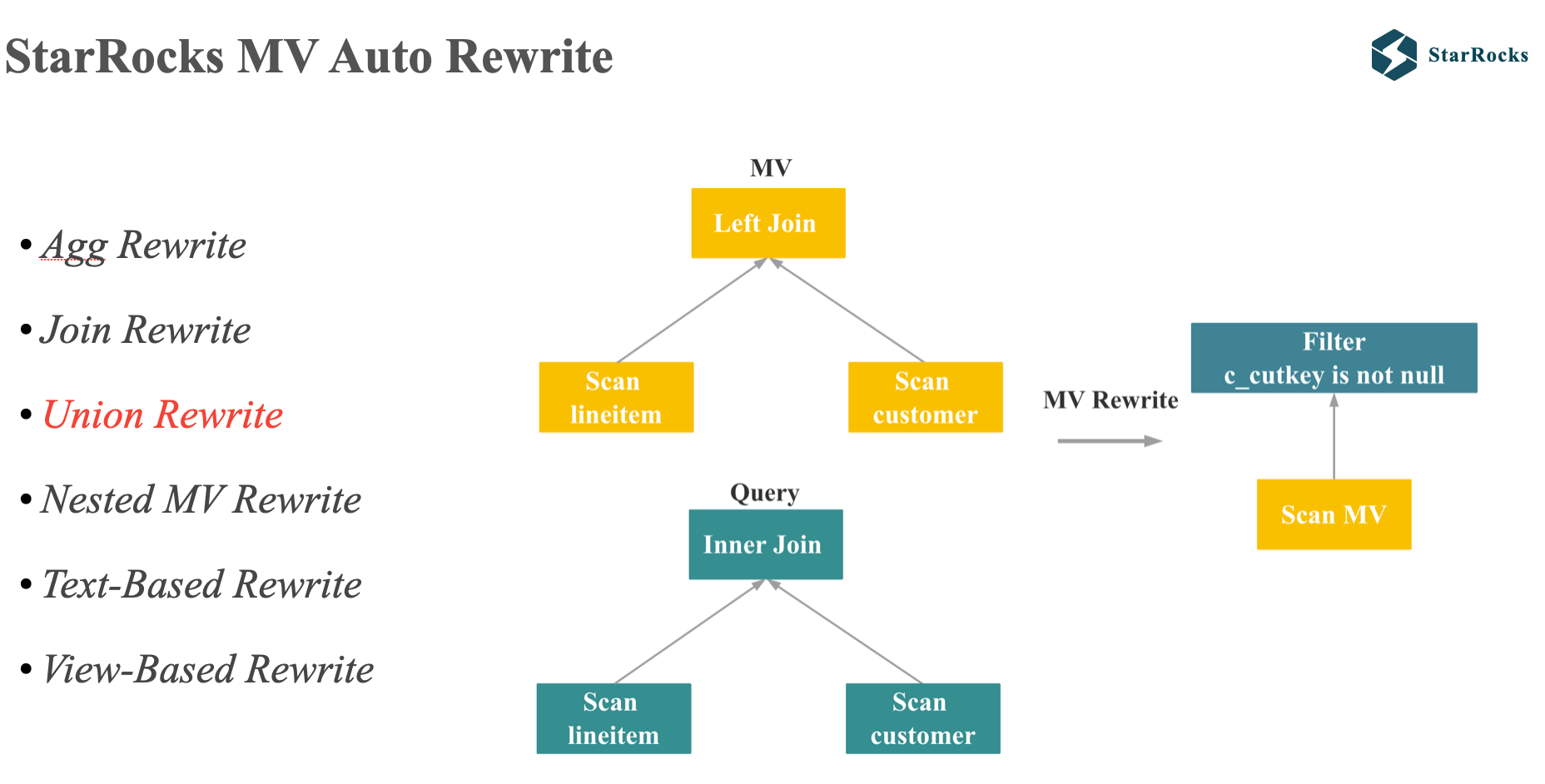
目前 StarRocks 支持很多场景的 Auto Rewrite,包括 聚合 rewrite,多种 join rewrite,union rewrite, Nested MV Rewrite,复杂 SQL 的 Text-Based Rewrite 和 view based 的 rewrite 等。 今天会介绍下 union rewrite。
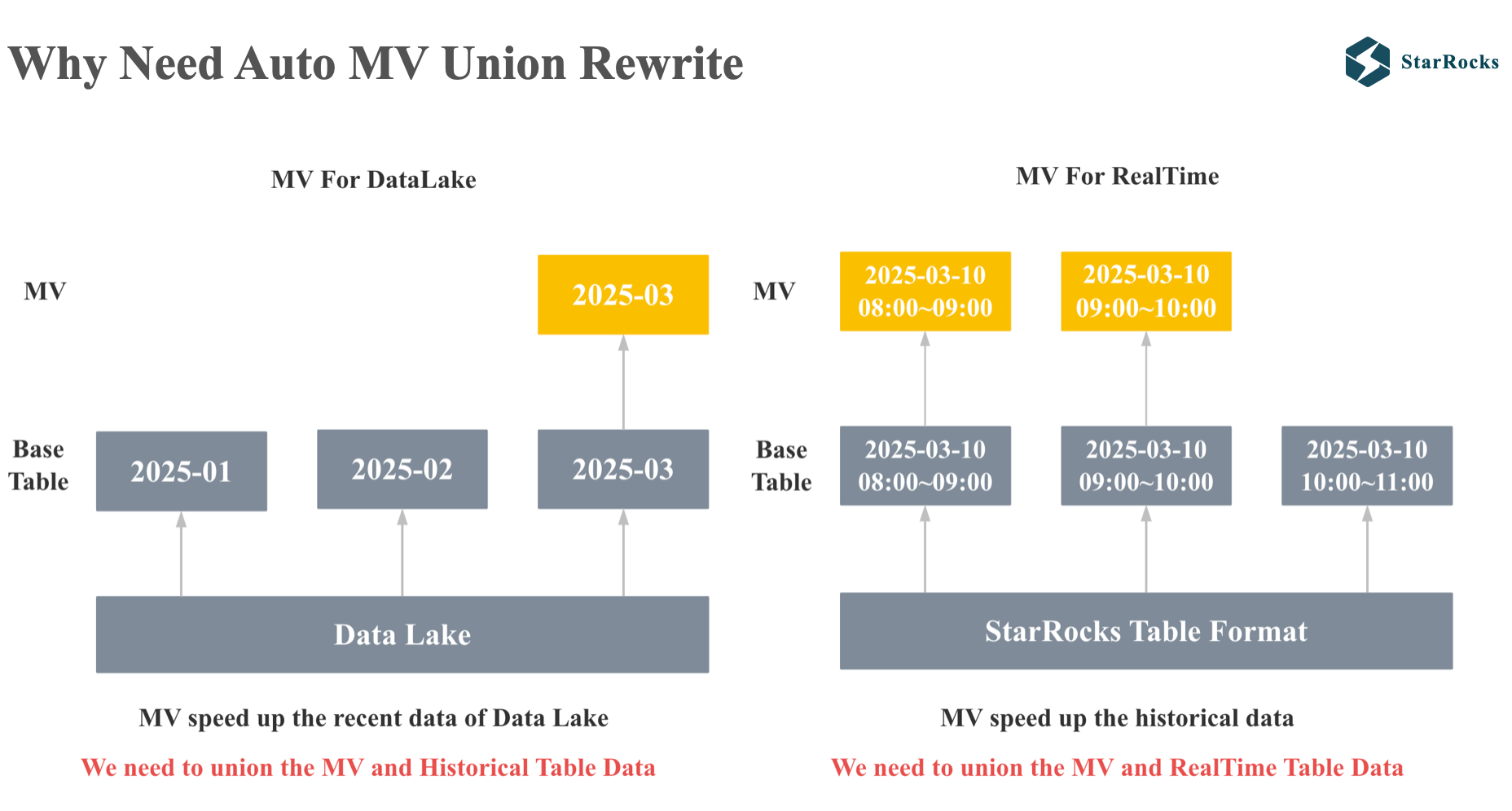
首先,我们来看下为什么需要 MV union rewrite:
第一个 case 是 query on lake 场景,starrocks 可以直接查询各种 data lake 的 table format,如果你期望获得压秒级性能,可以利用 MV 加速 data lake 上的查询,但是大部分用户重点只关注最近一段时间的查询性能,所以只需要对最近一周或者最近一月的数据构建 MV。 但是用户可能偶尔会对最近二周或者最近两月的数据发起查询,这时候就需要优化器自动改写查询,将近期的 MV 数据和 data lake 上的 union。
第二个 case 是实时场景,我们期望利用 MV 实现毫秒级查询,上万 QPS,但是 MV 的刷新有时延,无法保证最新的数据和 base 表一致。 为了向用户提供正确的,最新的查询结果,我们需要将 MV 的数据和 base 表最新的数据进行 Union。
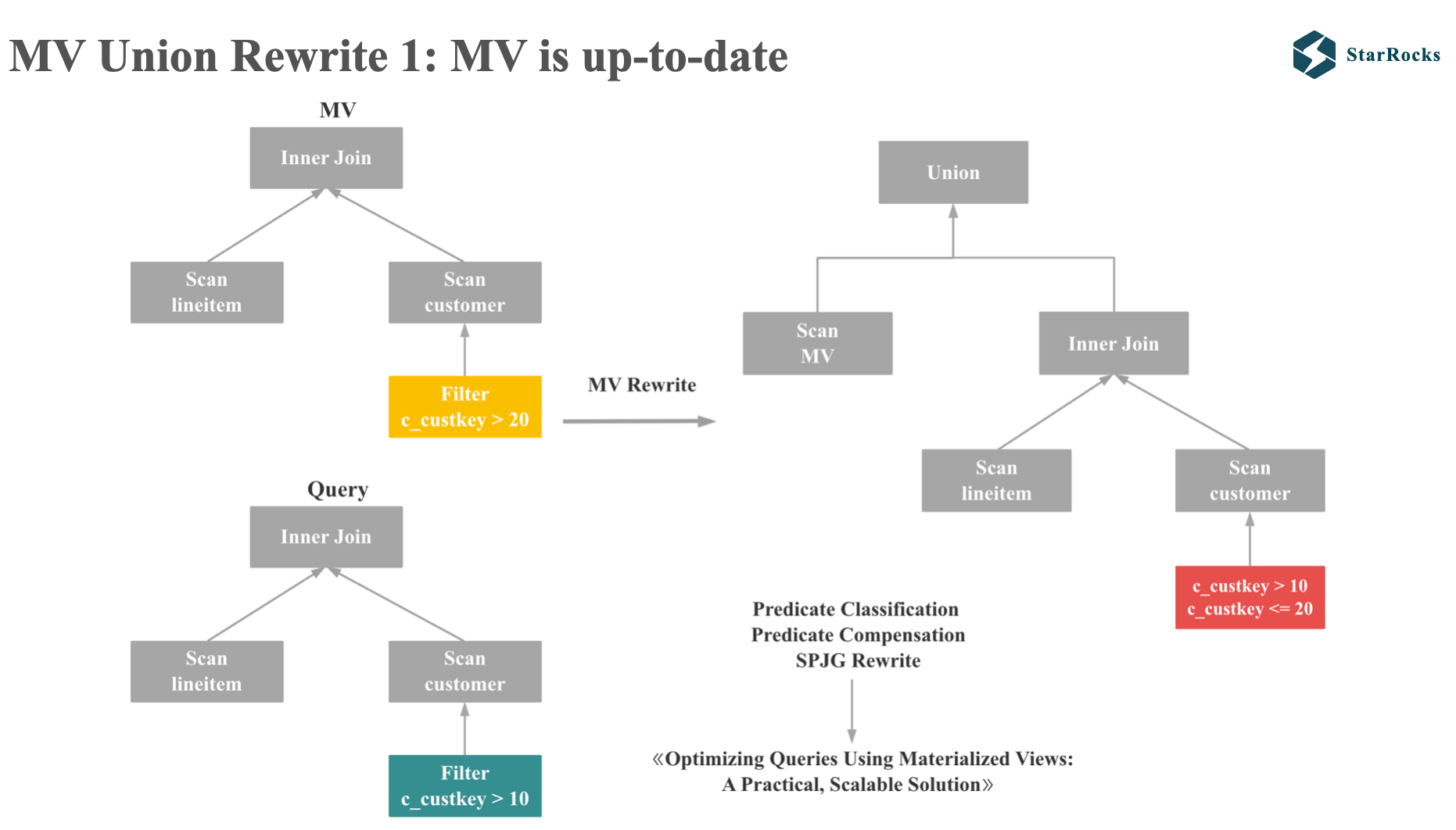
让我们首先考虑下 MV 所有分区全部刷新的 case:
如图,query 和 MV 都是两个很简单的 inner join,只是谓词范围不同,因为 MV 的结果集是 query 结果集的子集,所以我们需要生成一个新的补偿谓词加到原始的 query 上,最终再 union 起来。
这里 StarRocks 中谓词分类和谓词补偿的逻辑和微软的论文 《Optimizing Queries Using Materialized Views: A Practical, Scalable Solution》 一致。
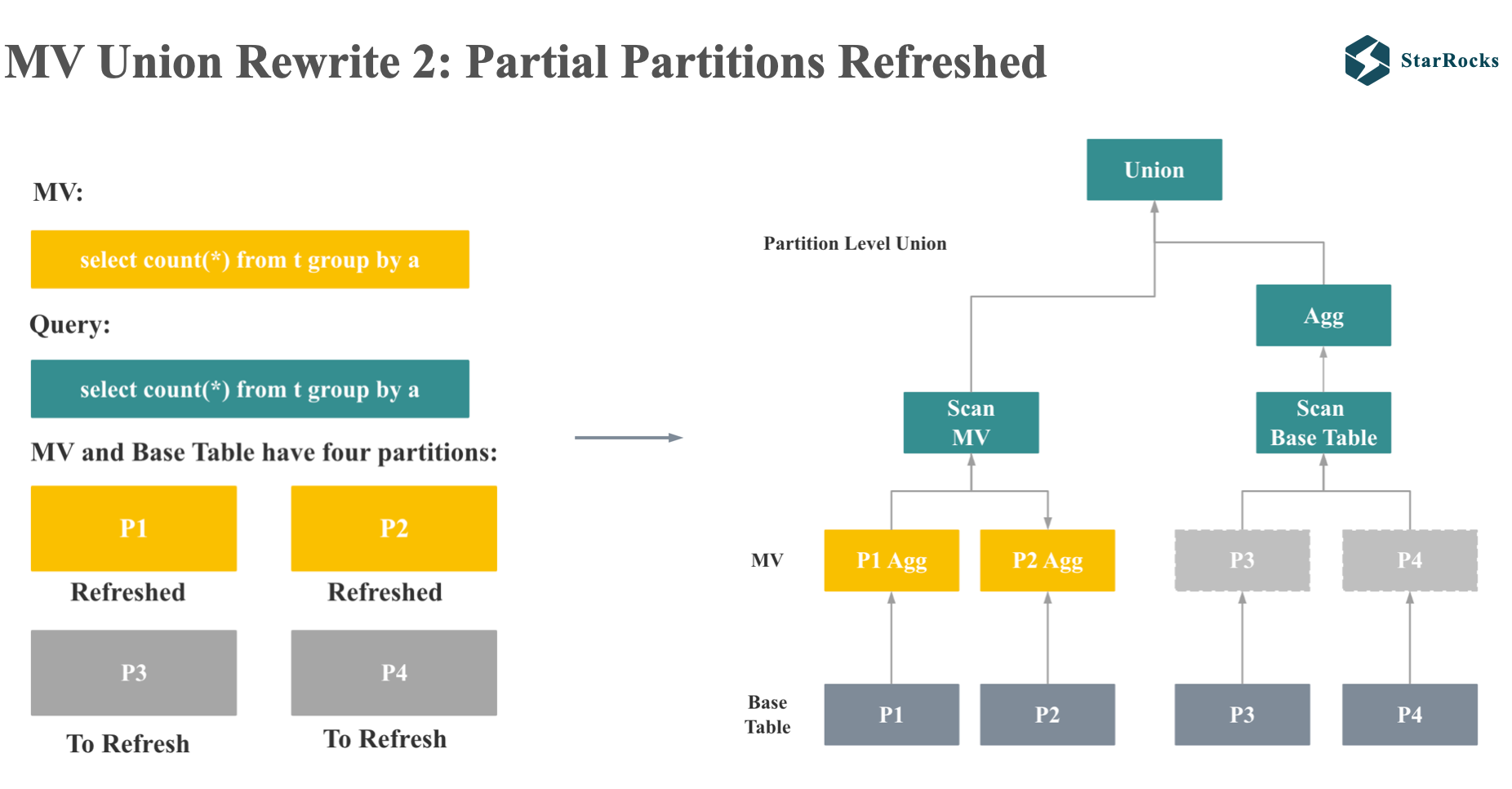
接下来,我们考虑下 MV 分区部分刷新的 case:
假如 MV 和 query 都是简单的 group by count 查询,MV 和 base 表都有 4 个分区,其中 MV 的 P1 和 P2 分区已经刷新了,但是 P3 和 P4 没有刷新。 这个聚合查询的改写就会变成 MV 查询和原始表的查询的 union。
union 的左孩子就是 MV 的 scan 节点,union 的右孩子就是原始查询的 plan,区别只是 Scan 的分区变成了 MV 未刷新的分区。
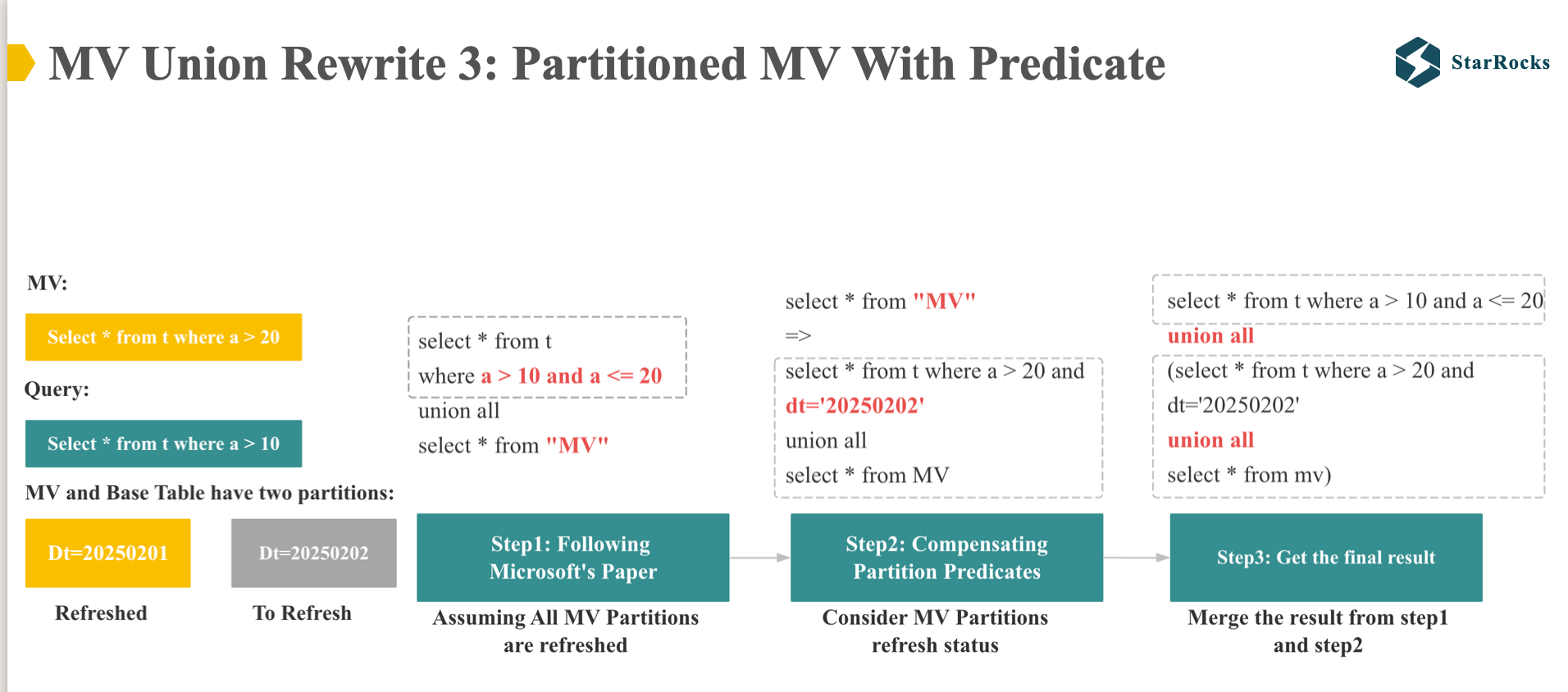
最后,让我们考虑下 Partitioned MV With Predicate 改写的 case:
假如,base 表有两个分区,0201 的分区对应的 MV 已经刷新了,0202 的分区 MV 还没有刷新。
- MV 的定义是
select * from t where a > 20 - Query 的定义是
select * from t where a > 10
结合前面介绍的 2 类改写 Case,我们的改写过程可以分为 3 步:
-
先在空间维度进行改写,忽略时间维度,认为 MV 的所有分区都已经刷新。 此时我们就按照微软的论文方法进行改写。
-
我们再考虑 MV 的新鲜度和分区刷新的状态,对第一步中 “MV” 的 Scan 增加分区的补偿谓词。
-
将前两部的结果进行整合,得到最终的结果。
Cost 估计的挑战和解决方案
Cost 估计的挑战

过去几年,在 cost estimation 部分,我们持续遇到了很多挑战,这也是所有 CBO 优化器都会遇到的挑战, 例如:
- 没有统计信息
- 抽样统计信息收集不准
- 抽样统计信息估计不准
- 即使统计信息准确,cost 估计也会出错(因为独立,不相关的基础假设不成立,或者多级 join 的误差层层放大)
- 还有生产环境常见的数据倾斜问题
- 还有最近一年部分用户暴露的生产环境 plan 抖动的问题,会导致正常的小查询变成大查询,导致生产环境事故。
今天我会主要介绍下 Query Feedback,Adaptive Execution 和 SQL Plan Management。
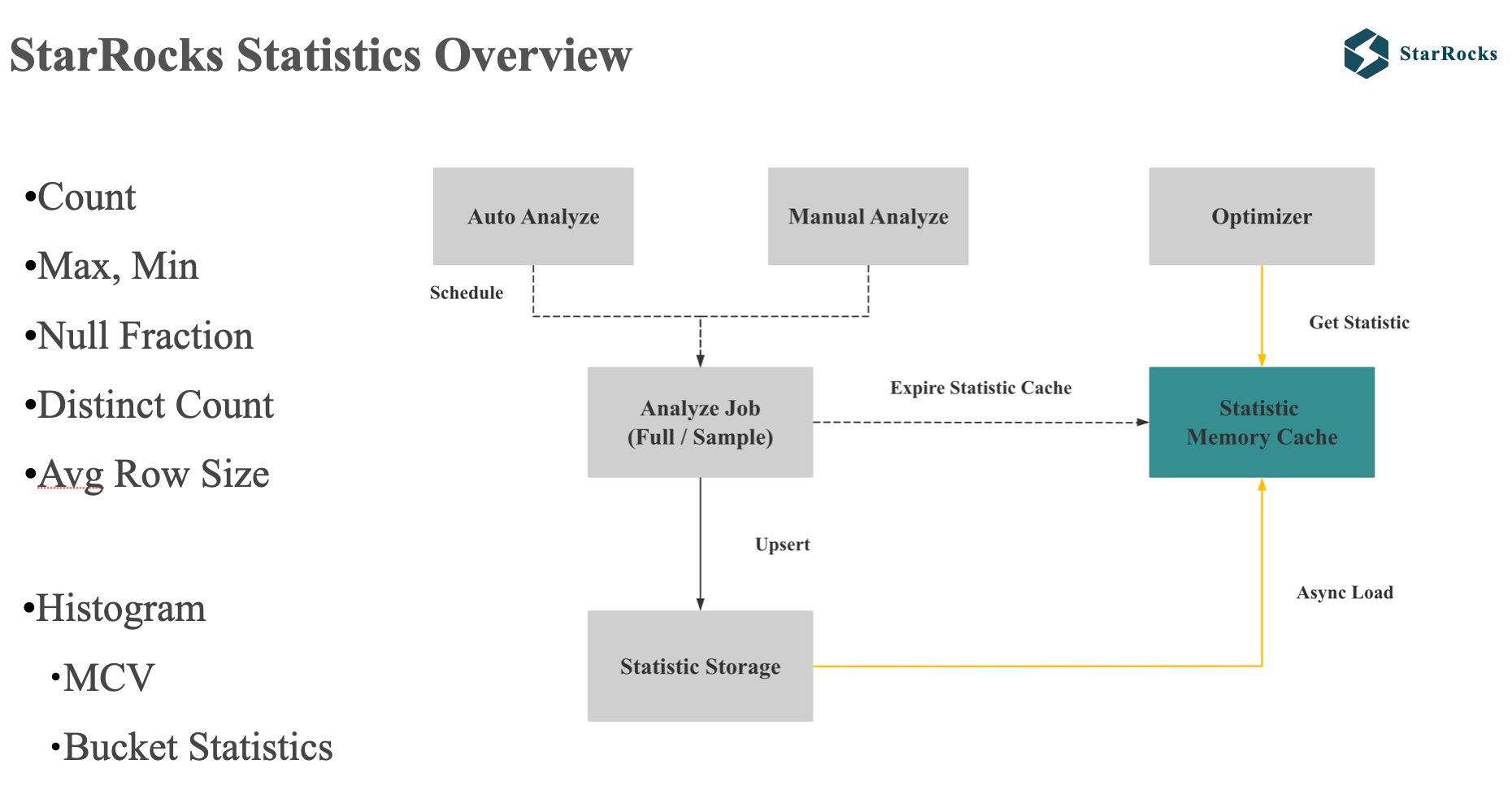
在介绍这几个高级功能前,我首先简单介绍下 StarRocks Statistics 相关的基本信息:
首先 StarRocks 的单列统计信息包括基础的 count,max, min, Distinct,也支持 Histogram。
StarRocks 的统计信息支持手动和自动收集,每种收集都支持全量和抽样两种方式。 为了减少查询 plan 的耗时,统计信息会 cache 在 FE 的内存中,优化器可以直接从内存中获取 column 的统计信息。
StarRocks 默认的自动收集是会对小表做全量收集,对大表做抽样收集。
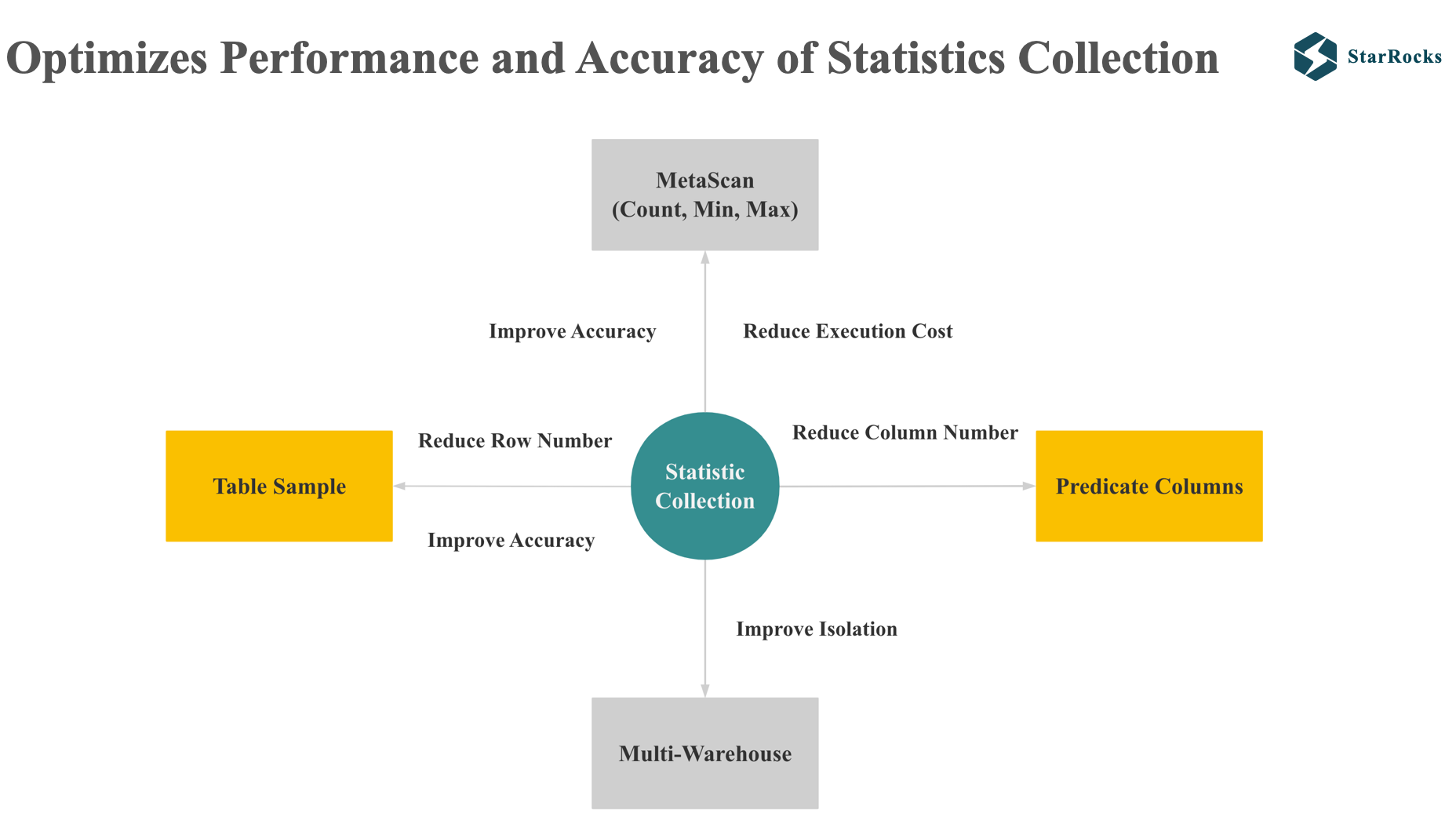
统计信息收集的难点是要在资源消耗和准确度之间进行权衡,同时也要避免统计信息收集任务影响正常的导入和查询。
StarRocks 在以下 4 个方面优化了统计信息收集的准确度和性能。
-
第一个点是 meta scan。 starrocks 对 count,min,max 的统计信息,会利用 meta scan 进行优化,减少了资源消耗。
-
第二个点是 table sample,在抽样的时候,会在只 Scan 少量数据的情况下尽可能提升准确度
-
除了从减少 scan 行数的角度降低统计信息收集的成本,starrocks 也会从减少 scan 的列数来降低统计信息的成本。 table sample 和 predicate column 下面都会介绍到。
-
最后一点是减少统计信息收集对正常查询和导入的影响,starrocks 目前支持将统计信息任务在单独的 warehouse 中执行,这样就保证了统计信息收集的 job 不会影响集群中查询和导入请求。
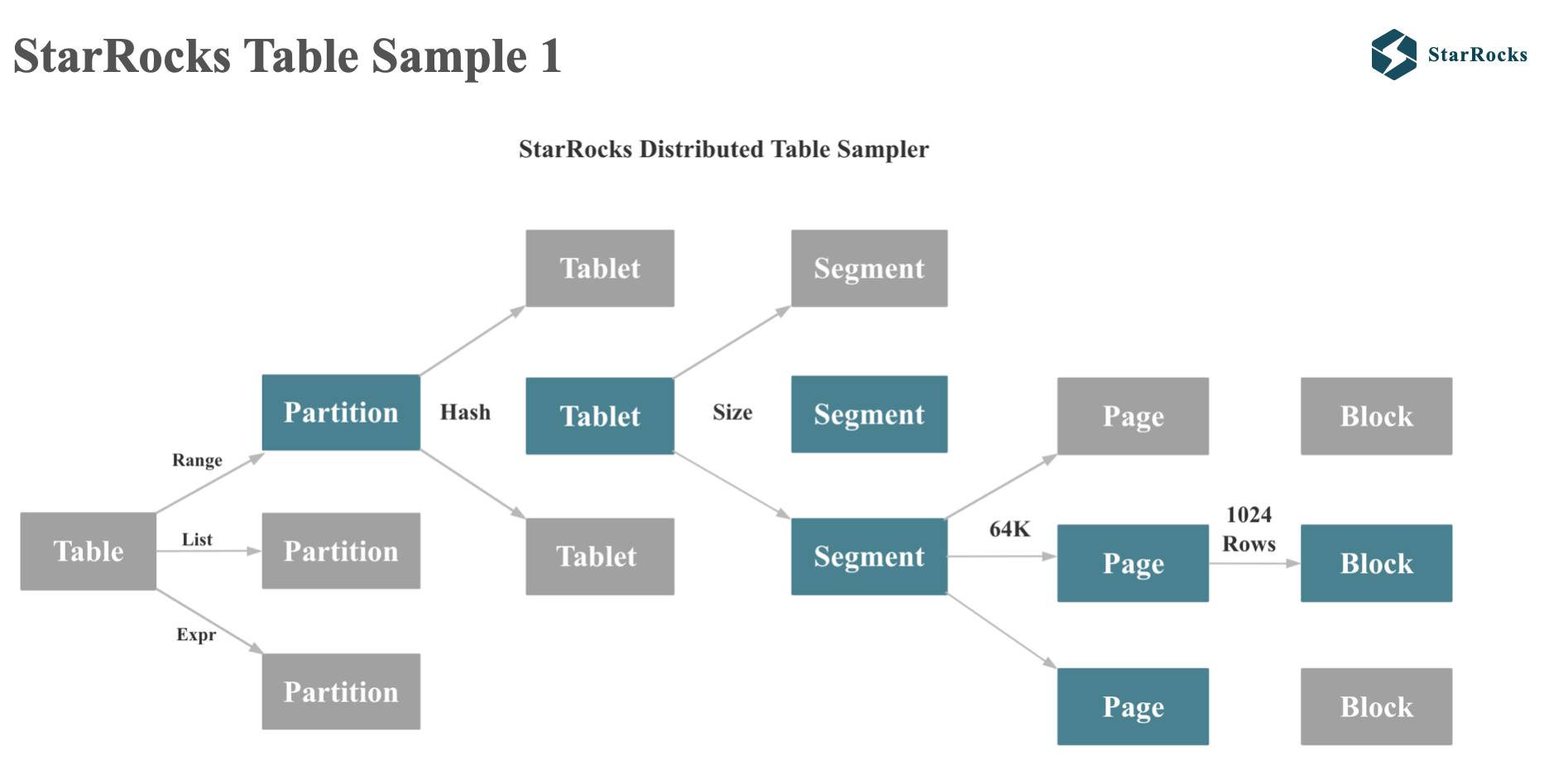
StarRocks 的 table sample 会遵循 starrocks 每个表的真实物理分布。大家从图中可以看出,starrocks 的 table 会先根据 range 或者 list 分区,然后再跟进 hash 或者 random 分桶。 每个 tablet 会根据 size 分成多个 segment,segment 是不可变的,segment 的每个 column 会根据每 64kb 划分成多个 page。 page 是最小的 IO 单位。
StarRocks 在抽样统计时,会抽取部分 tablet,部分 segment 的数据。
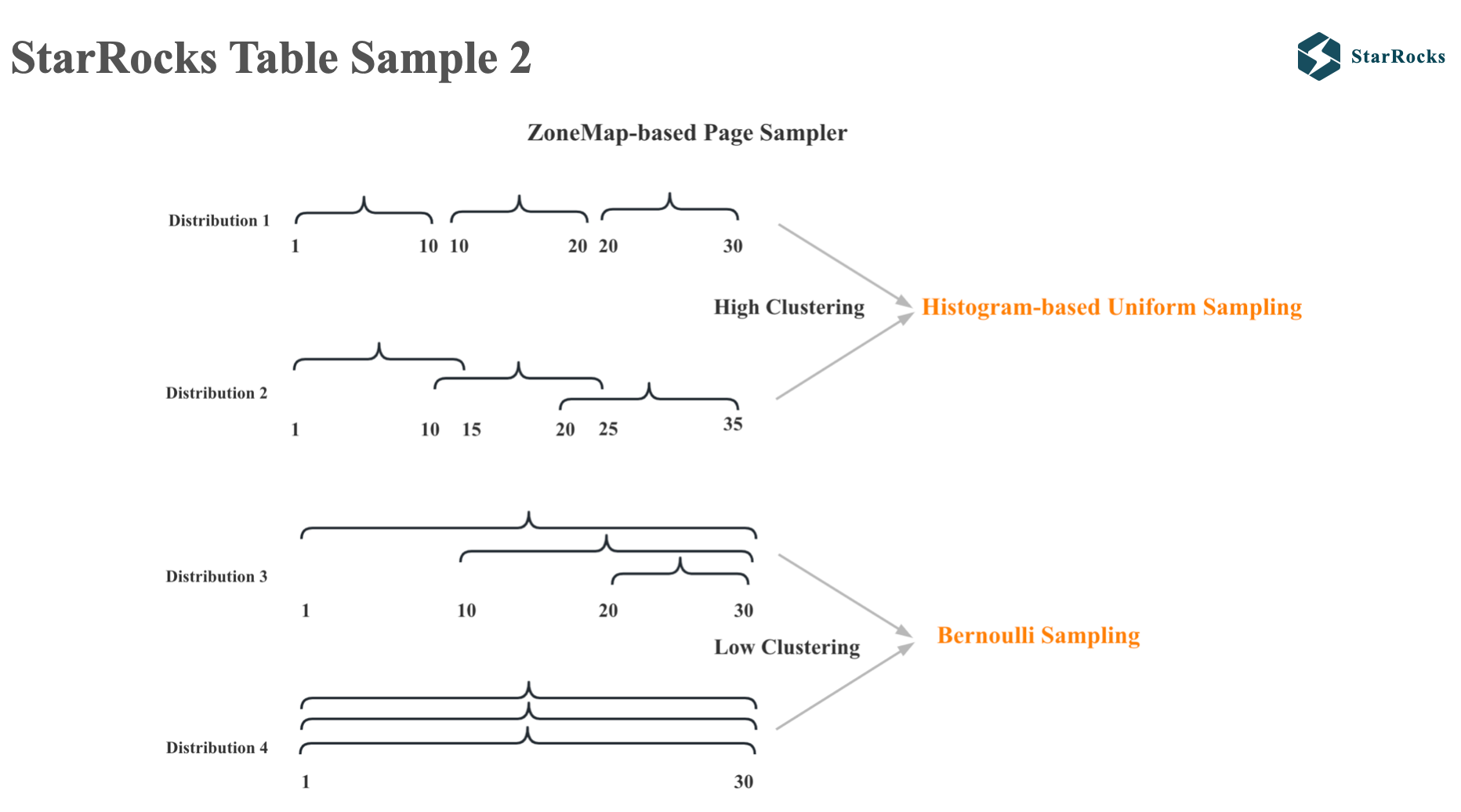
至于每个 segment 内读取哪些 page 的数据,StarRocks 会根据不同的数据分布特点采用不同的抽样算法。 StarRocks 会先根据每个 page 的 zonemap 的 max 和 min 值对 pages 进行排序,如果发现数据的聚类程度很高,就会采用 histogram based 的 uniform 的 sample 算法。 如果发现数据的聚类程度很低,就会采用 bernoulli sample 算法

之前提到的 Predicate Columns 核心思想十分简单,就是我们认为当一个表有成百上千列时,只有少数关键列的统计信息会对最终的 plan 质量产生影响,在 olap 分析中,这些列一般是维度列。比如 filter columns,group by columns,distinct columns 和 join on columns。
所以当列很多时,我们只需要对 维度列或者 Predicate Columns 进行统计信息收集就可以了。
StarRocks Query Feedback
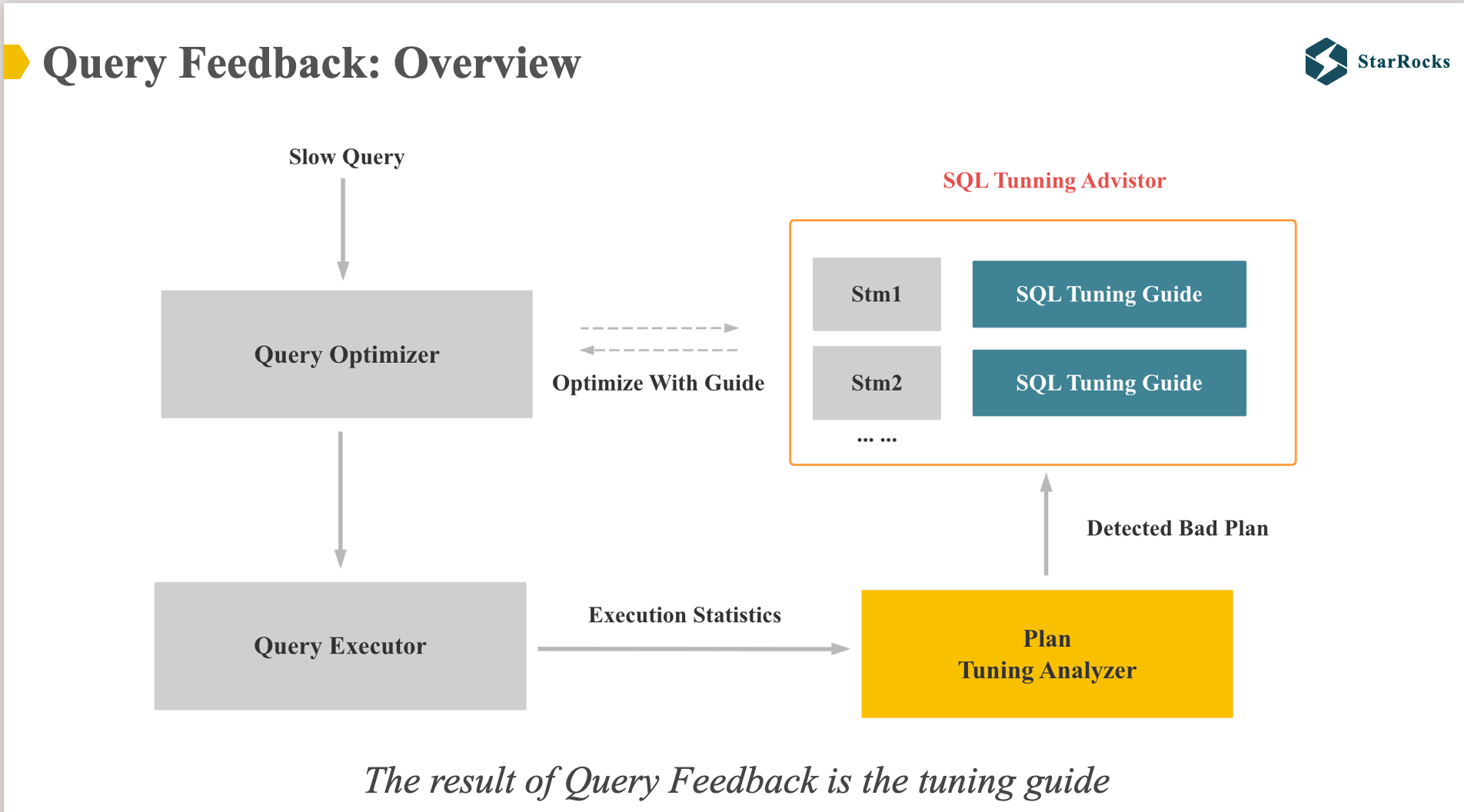
前面提到 query feedback 是为了解决因为任何原因导致的 cost 估计不准的问题,核心思路是利用真实的运行时信息去纠正 优化器的 plan,让优化器下一次产生更好的 plan。
StarRocks 的 query feedback 第一个版本没有更新统计信息,而且记录了每类查询应该对应的更好的 tuning guide。
图中可以看到,Query Feedback 有两个核心模块:plan tuning analyzer 和 sql tuning advisor.
plan tuning analyzer 会根据查询的真实运行时信息和执行 plan,检查是否有明确的 bad plan。如果检测到有明确的 bad plan,就会记录下来。
当优化器产生了最终的 plan 后,如果发现 sql tuning advisor 中有记录对应的 tuning guide,就会 apply tuning guide 中更优的 plan。
目前 Query Feedback 的第一个版本主要可以优化 3 类 case:
- 优化 Join 左右表顺序
- 优化 Join 的分布式执行策略
- 优化 自适应的 streaming 聚合策略,如果发现第一阶段聚合效果好,就会在第一阶段的 Local 聚合进行全量聚合
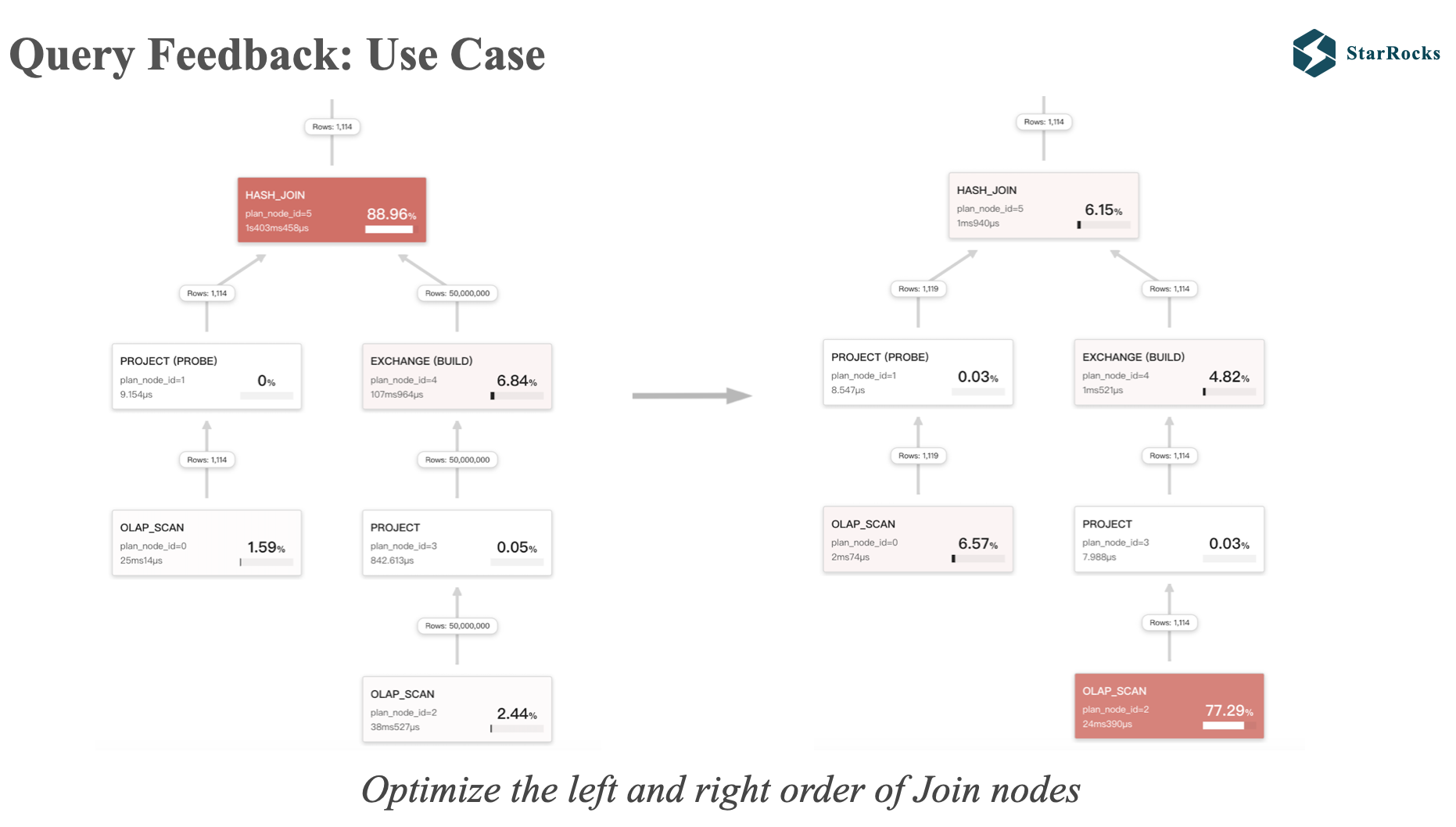
这是一个 Query Feedback 的应用案例,将错误的 Join 左右表顺序调整正确。
左边是 50000000 行的大表在右边,1114 行的小表在左边,当用大表构建 hash 表时,性能就会很差。
同时大家也发现在右边的 Query Profile 中,左表的数据只有 1119 行,这是因为 runtime filter 生效了,将左表的数据过滤掉了,runtime filter 之后我会介绍到。 大家可以看到,两种不同 plan 的查询耗时 有数量级的差别。
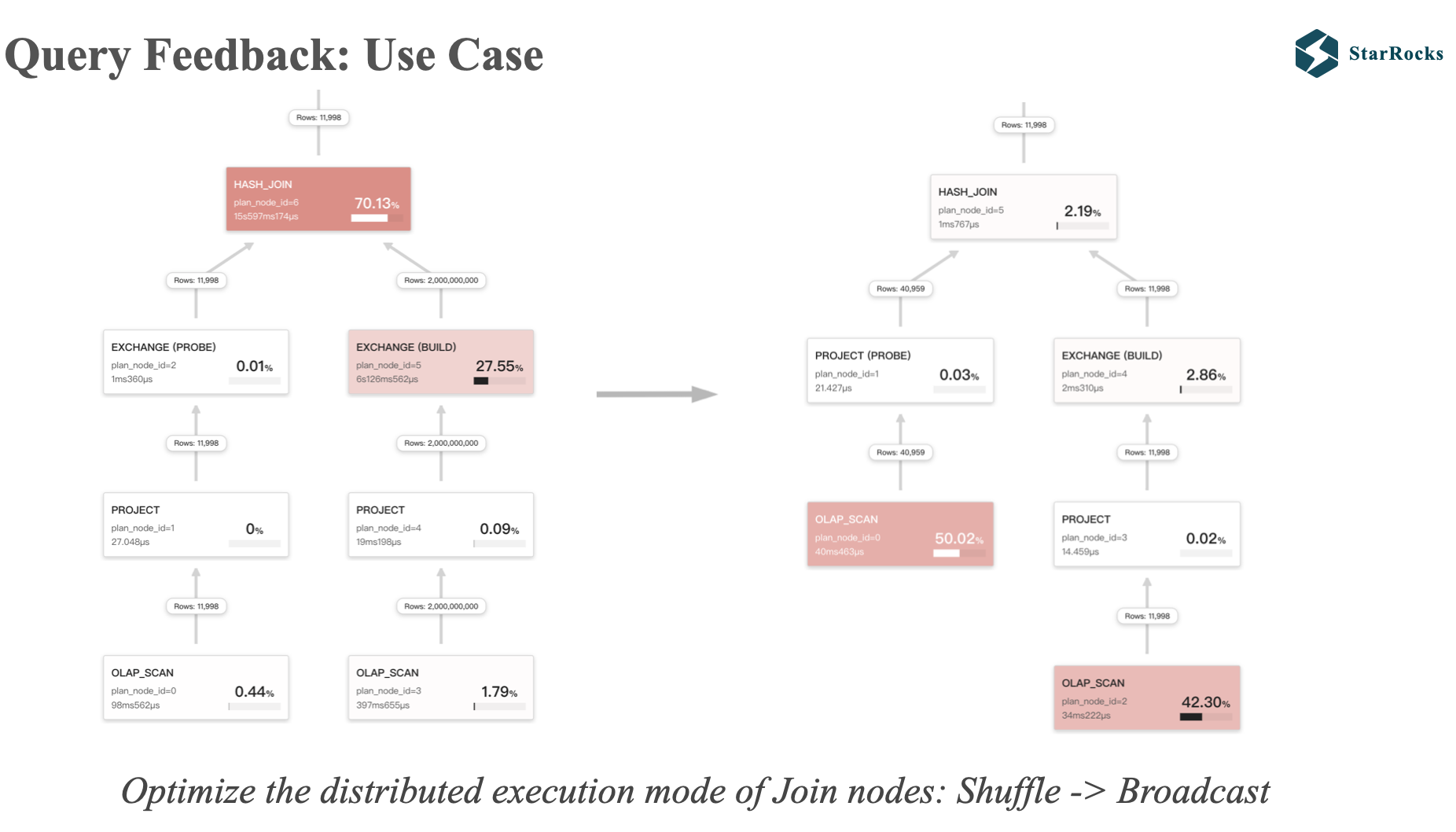
这是 Query Feedback 的第二个应用案例,将错误的 shuffle join 调整成 broadcast join
如图,左边 join 的左右两个孩子都是 exchange,说明是 shuffle join,但是我们发现左表的数据只有 11998 行,显然 broadcast join 是更优的执行策略。
应用 feedback tuning 后,shuffle join 被调整成 broadcast join,同时 runtime filter 也生效了。 同时大家也可以看到,两种不同 plan 的查询耗时也有数量级的差别。
StarRocks Adaptive Execution
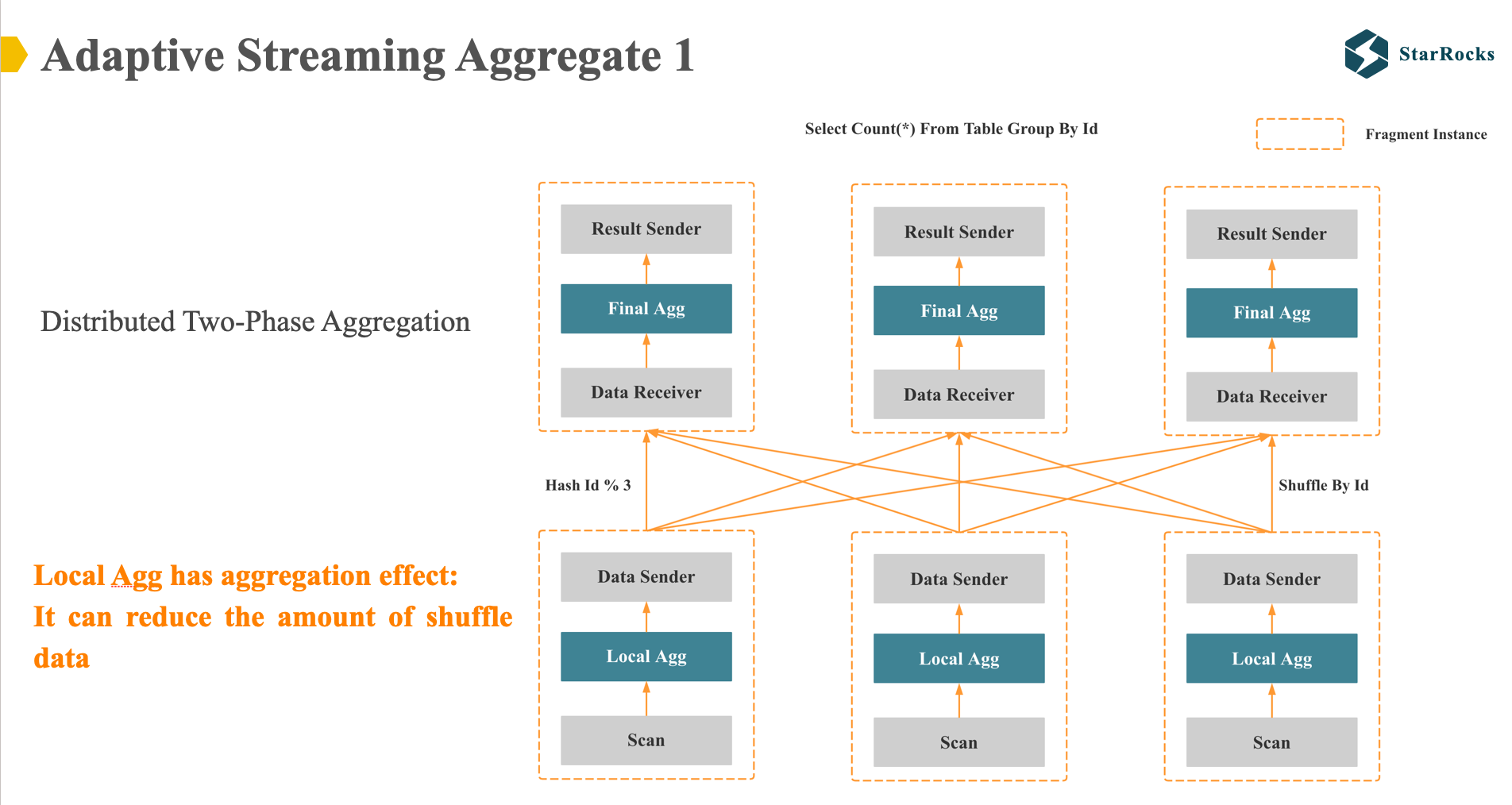
下面我们了解下 Adaptive Streaming Aggregate。对于简单的 group by 查询: select count(*) from table group by id, 如果是非 colocate 表,StarRocks 会产生两种的分布式执行计划。
第一种是分布式两阶段执行:如图,在第一阶段,starrocks 会将数据先根据 id 列用 hash 表进行聚合,然后通过 hash shuffle 的方式将相同 id 的数据都发送到相同的节点上。在第二个阶段,会做第二次的 hash 聚合,然后向客户端返回最终结果。
我们为什么需要在第一阶段进行一次 local 聚合呢?
因为我们期望通过第一次聚合,减少 shuffle 网络传输的数据量。 显然,这里的假设是,第一次 local 聚合会有聚合效果,一般对中低基数列适用。
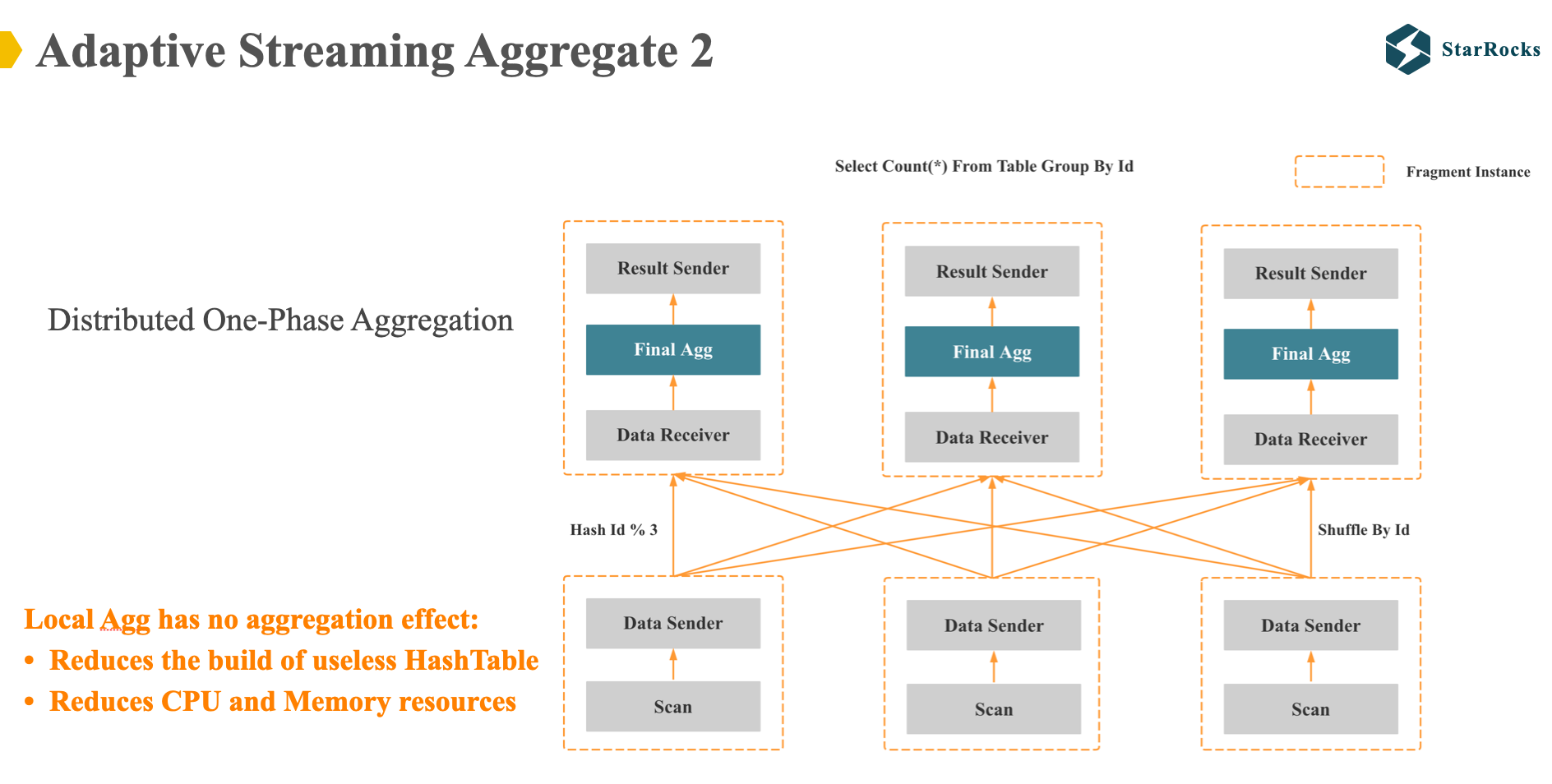
StarRocks group by 的第二种分布式执行计划就是一阶段聚合: 就是在 scan 数据后直接 shuffle 数据,然后做一次聚合。
显然。一阶段聚合适合 local 聚合没有聚合效果的 case,适合高基数 group by 列。
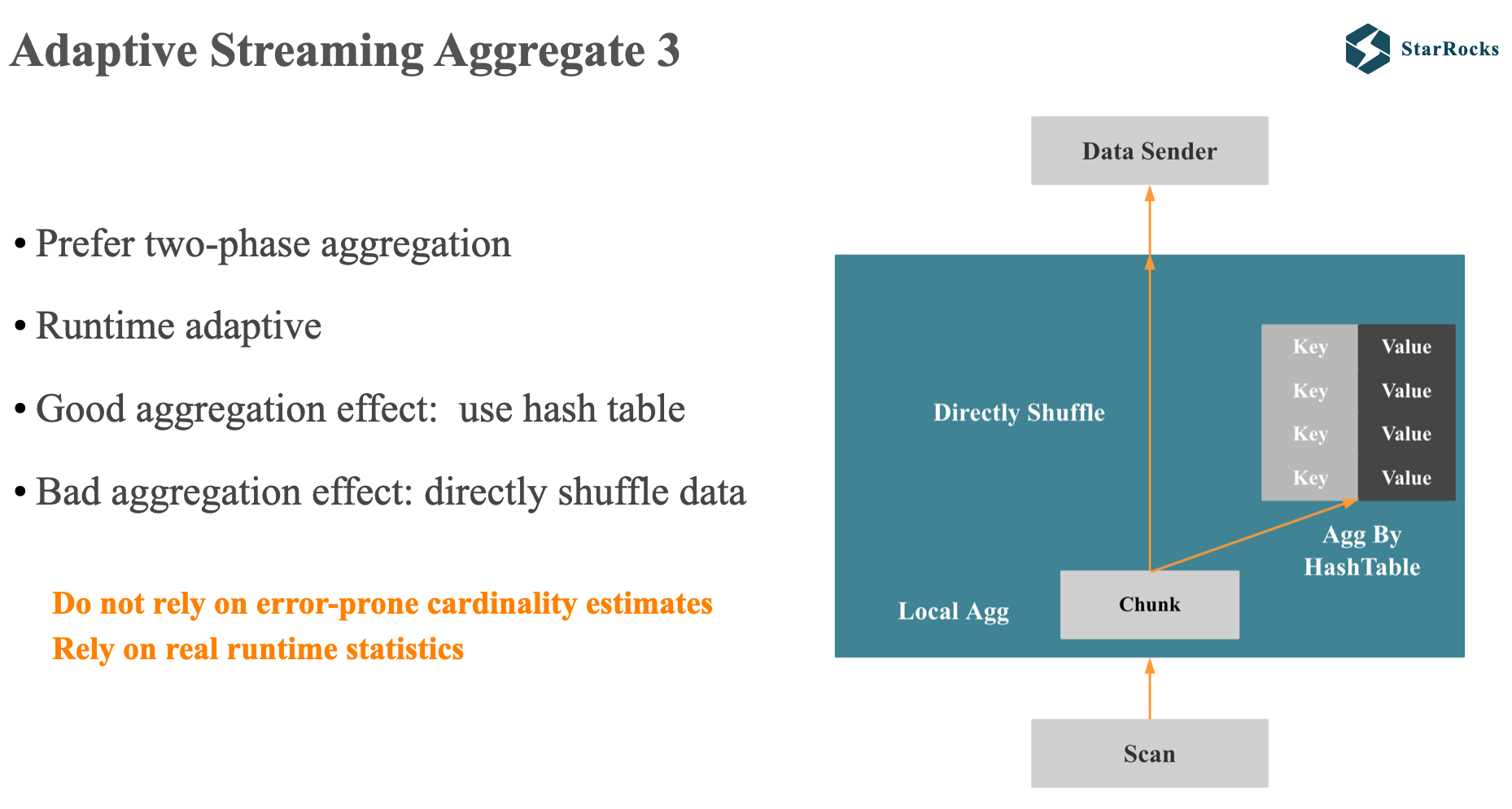
理论上讲,只要优化器可以将 group by 的基数估计准确,我们就可以直接选择出正确的 1 阶段或者 2 阶段计划。 但是对于 多列 group by 基数估计来讲,这是十分有挑战的,因为 group by 的多列一般不是独立的,而且有相关性的。
所以,在 StarRocks 中,我们没有在优化器方向去解决这个问题,而是希望在执行层自适应来解决这个问题:
StarRocks 的优化器会倾向出分布式 2 阶段聚合计划,然后根据执行时获得的真实聚合效果动态进行自适应调整。
如图所示,StarRocks 自适应聚合的原理如下:
在 local 聚合中,每过一批数据,假设是 100 万行,StarRocks 会先利用 hash 表去聚合数据,当发现没有聚合效果时,就不会再将数据加入到 hash 表中,而是直接进行 shuffle,避免进行无意义的 hash 聚合。
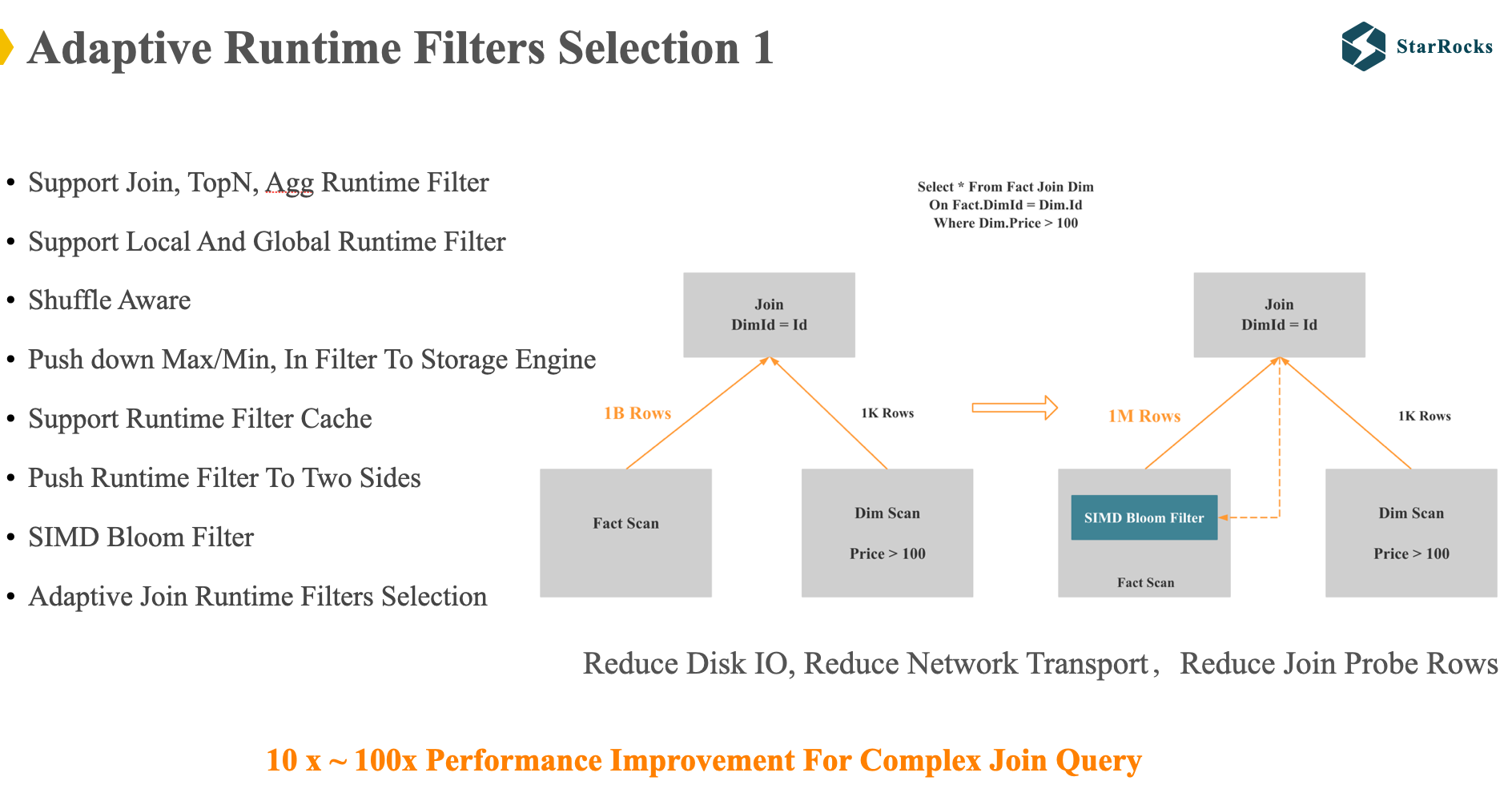
下面我们再来看另一个自适应执行的 case:Adaptive Runtime Filters Selection。首先我们快速了解下 什么是 runtime filter,runtime filter 在一些 paper 中也叫 Sideways information passing。
图中是 join runtime filter 的简单示意,StarRocks 的等值 join 都是 hash join,StarRocks 就会将右表数据构建 bloom filter,下推到左表。 runtime filter 可以在 join 前提前过滤左表的数据,减少 IO,网络和 CPU 资源。
对于复杂 SQL,runtime filter 会有几十倍的性能提升。 过去 5 年,StarRocks 一直在持续优化改进 runtime filter,左边列出的是 StarRocks runtime filter 的一些特点。
但是 runtime filter 可能会有负优化:当 join 的表很多,join on 的条件很多时,可能会下推很多个 runtime filer, 这会导致下面的问题:
- 一些 runtime filter 没有过滤效果,浪费了 CPU 资源
- 先利用选择度很高的 filter 进行过滤,一些选择度很低的 filter 最后才应用,同样浪费了 CPU 资源

一些数据库可能会依靠优化器来估算 runtime filter 的选择度,然后根据选择度对将 filter 进行排序。 StarRocks 选择利用 Adaptive Execution 来解决这个问题。
如图,StarRocks 每过一定行的数据,会计算每个 runtime filter 的真实选择度,然后自适应调整 runtime filter 的应用, 这是一些基本的调整原则:
- 只选择 selectivity 较高的 filter
- 最多只选择 3 个 filter
- 如果一个 filter 的 selectivity 特别高,则只保留一个 filter
SQL Plan Management
最后,我们介绍下 SQL Plan Management,这个 feature 我们正在开发中,目前刚合入第一版代码。
我们决定开发这个功能,是过去一年多,一些用户线上由于 plan 抖动导致小查询变成了大查询,导致了生产事故。
我们期望通过 SQL Plan Management 解决两个问题:
- 保证升级后不会因为 plan 变动导致明显的查询性能回退
- 保证线上持续运行的重要业务的查询 plan 不会变差

SQL Plan Management 在原理上分为两部分:
1 如何生成和保存 baseline plan 2 如何应用 baseline plan
如何生成 Baseline Plan 分为 3 步:
- 常量的参数化:会将 sql 的常量替换成特殊的 SPMFunctions
- 生成 plan: 根据参数化的 plan 生成分布式 physical plan
- 生成 baseline SQL: 将 physical plan 转成带 hint 的 SQL。 大家可以看到 shuffle 和 bucket 的 hint 几乎确定了这个 SQL plan 的两个重点: join order 和 join 分布式执行策略。(StarRocks 对有 hint 的 join sql 不会进行 reorder)
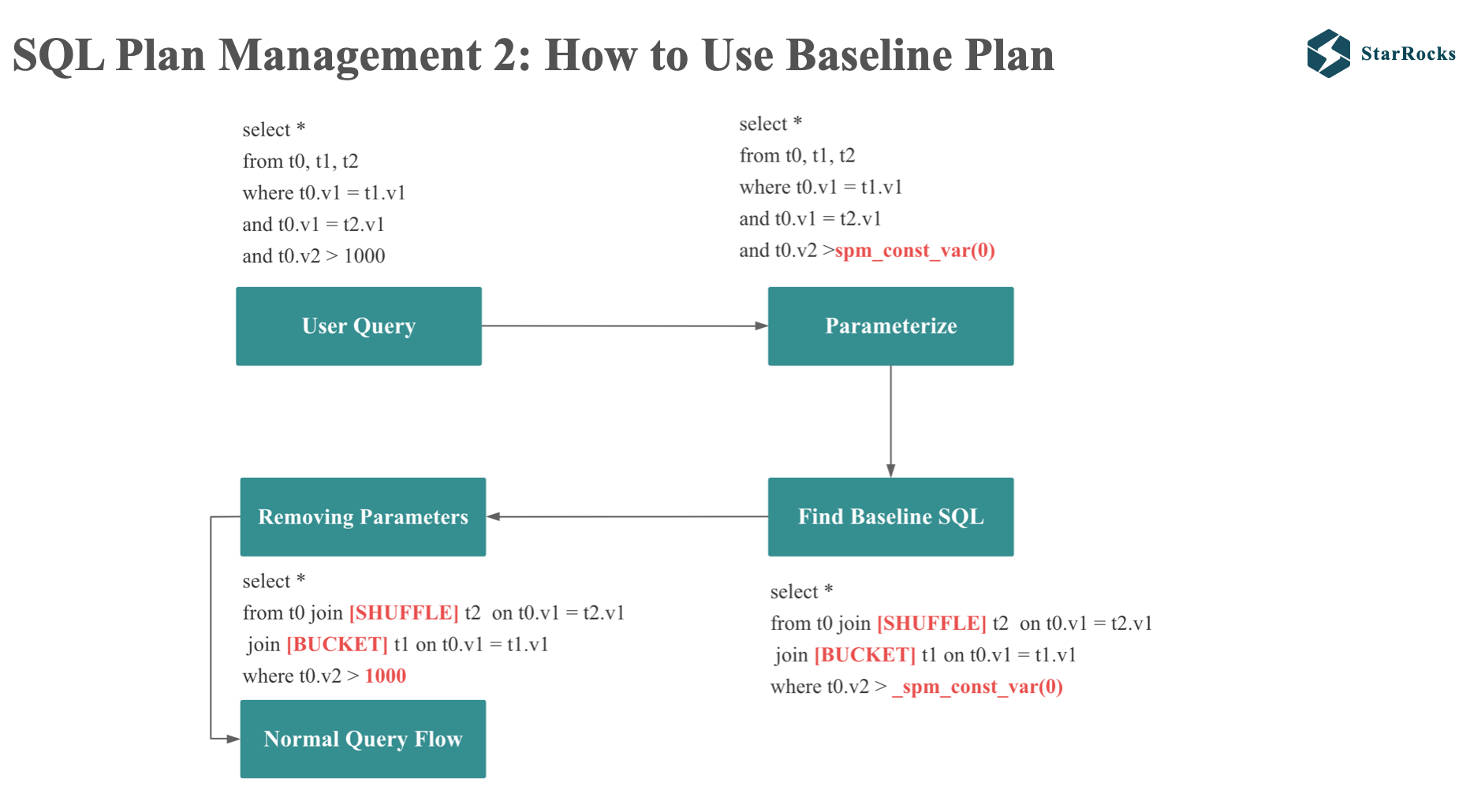
使用 baseline plan 分为 4 个步骤:
- 常量的参数化:会将查询的常量替换成特殊的 SPMFunctions
- 获取 baseline SQL: 会将参数的 SQL 计算 Digest,根据 Digest 在 plan storage 中找到对应的 baseline SQL
- 将 baseline SQL 中的 SPMFunctions 替换成输入 SQL 的常量
- 然后按照正常的查询流程处理带有 hint 的 SQL
FAQ
StarRocks 的 Join Reorder 算法
StarRocks 优化器实现了多种 Join Reorder 算法,根据不同的 Join 数量使用不同的算法:
- Join 数量小于等于 4 时,使用 Join 结合律 + Join 交换律
- Join 数量小于等于 10 时,使用左深树 + 动态规划算法 + 贪心算法
- Join 数量小于等于 16 时,使用左深树 + 贪心算法
- Join 数量小于等于 50 时,使用左深树
- Join 数量大于 50 时,不进行 Join Reorder
如何优化 Join Reorder 和 分布式策略的组合爆炸问题
-
对 Join Reorder 的结果数量进行限制
- 左深树和动态规划算法 只会产出一种 Join Reorder 结果
- 贪心算法只会取 Top K 个 Join Reorder 结果
-
在探索搜索空间时,会基于 lower bound 和 upper bound 进行剪枝
Query Feedback 和 Plan Management 是否支持参数化
第一版本暂时不支持,不过我们今年会马上支持。思路是对参数的范围切分 range,让不同 range 的场景参数对应不同的 tuning guide 和不同的 baseline plan。
Lessons From StarRocks Query Optimizer
- 优化器成本估算中的错误是不可避免的,执行器需要能够根据运行时真实统计信息做出自主决策并提供及时反馈。这意味着 Cost-based 的优化器需要 Adaptive Execution 和 Query Feedback
- 在工程中,优化器测试系统和优化器本身一样重要,优化器需要进行正确性测试、性能测试、计划质量测试等。或许整个数据库开源生态还需要一个优秀的优化器测试系统和公开可复用的开源测试数据集。
- Null 和 Nullable 既有趣又烦人
- 为了提高性能,我们需要特别处理 Null 和 Nullable,尤其你的查询执行器是向量化执行器
- 为了保证正确性,我们需要在优化器和执行器中特别小心处理 Null 和 Nullable
- Integrated optimizer could be more powerful than Standalone optimizer
- 因为Integrated optimizer 更容易获取更多的上下文,所以更容易做更多的优化。例如 全局低基数字典优化,QueryFeedback 和 Adaptive Execution 等优化,都需要优化器和数据库其他模块的紧密配合
总结
由于时间限制,本次分享主要分享了 StarRocks 查询优化器的三个代表性优化和应对成本估计挑战的解决方案,大家如果对 StarRocks 查询优化器其他部分感兴趣,欢迎交流。
